
Synthetic Data SDK

Synthetic Data SDK ✨
Security
Synthetic Data SDK ✨



Documentation | Usage Examples | Free Cloud Service
The Synthetic Data SDK is a Python toolkit for high-fidelity, privacy-safe Synthetic Data.
- LOCAL mode trains and generates synthetic data locally on your own compute resources.
- CLIENT mode connects to a remote MOSTLY AI platform for training & generating synthetic data there.
- Generators, that were trained locally, can be easily imported to a platform for further sharing.
Overview
The SDK allows you to programmatically create, browse and manage 3 key resources:
- Generators - Train a synthetic data generator on your existing tabular or language data assets
- Synthetic Datasets - Use a generator to create any number of synthetic samples to your needs
- Connectors - Connect to any data source within your organization, for reading and writing data
| Intent | Primitive | API Reference |
|---|---|---|
| Train a Generator on tabular or language data | g = mostly.train(config) | mostly.train |
| Generate any number of synthetic data records | sd = mostly.generate(g, config) | mostly.generate |
| Live probe the generator on demand | df = mostly.probe(g, config) | mostly.probe |
| Connect to any data source within your org | c = mostly.connect(config) | mostly.connect |
https://github.com/user-attachments/assets/9e233213-a259-455c-b8ed-d1f1548b492f
Key Features
- Broad Data Support
- Mixed-type data (categorical, numerical, geospatial, text, etc.)
- Single-table, multi-table, and time-series
- Multiple Model Types
- State-of-the-art performance via TabularARGN
- Fine-tune HuggingFace-based language models
- Efficient LSTM for text synthesis from scratch
- Advanced Training Options
- GPU/CPU support
- Differential Privacy
- Progress Monitoring
- Automated Quality Assurance
- Quality metrics for fidelity and privacy
- In-depth HTML reports for visual analysis
- Flexible Sampling
- Up-sample to any data volumes
- Conditional generation by any columns
- Re-balance underrepresented segments
- Context-aware data imputation
- Statistical fairness controls
- Rule-adherence via temperature
- Seamless Integration
- Connect to external data sources (DBs, cloud storages)
- Fully permissive open-source license
Quick Start 
Install the SDK via pip (see Installation for further details):
pip install -U mostlyai # or 'mostlyai[local]' for LOCAL mode
Generate synthetic samples using a pre-trained generator:
# initialize the SDK
from mostlyai.sdk import MostlyAI
mostly = MostlyAI()
# import a trained generator
g = mostly.generators.import_from_file(
"https://github.com/mostly-ai/public-demo-data/raw/dev/census/census-generator.zip"
)
# probe for 1000 representative synthetic samples
mostly.probe(g, size=1000)
Generate synthetic sampels based on fixed column values:
# create 10k records of 24y male respondents
mostly.probe(g, seed=[{"age": 24, "sex": "Male"}] * 10_000)
And now train your very own synthetic data generator:
# load original data
import pandas as pd
original_df = pd.read_csv(
"https://github.com/mostly-ai/public-demo-data/raw/dev/titanic/titanic.csv"
)
# train a single-table generator, with default configs
g = mostly.train(
name="Quick Start Demo - Titanic",
data=original_df,
)
# display the quality assurance report
g.reports(display=True)
# generate a representative synthetic dataset, with default configs
sd = mostly.generate(g)
synthetic_df = sd.data()
# probe for some samples
mostly.probe(g, size=100)
Performance
The SDK is being developed with a focus on efficiency, accuracy, and flexibility, with best-in-class performance across all three. Results will ultimately depend on the training data itself (size, structure, and content), on the available compute (CPU vs GPU), as well as on the chosen training configurations (model, epochs, samples, etc.). Thus, a crawl / walk / run approach is recommended — starting with a subset of samples training for a limited amount of time, to then gradually scale up, to yield optimal results for use case at hand.
Tabular Models
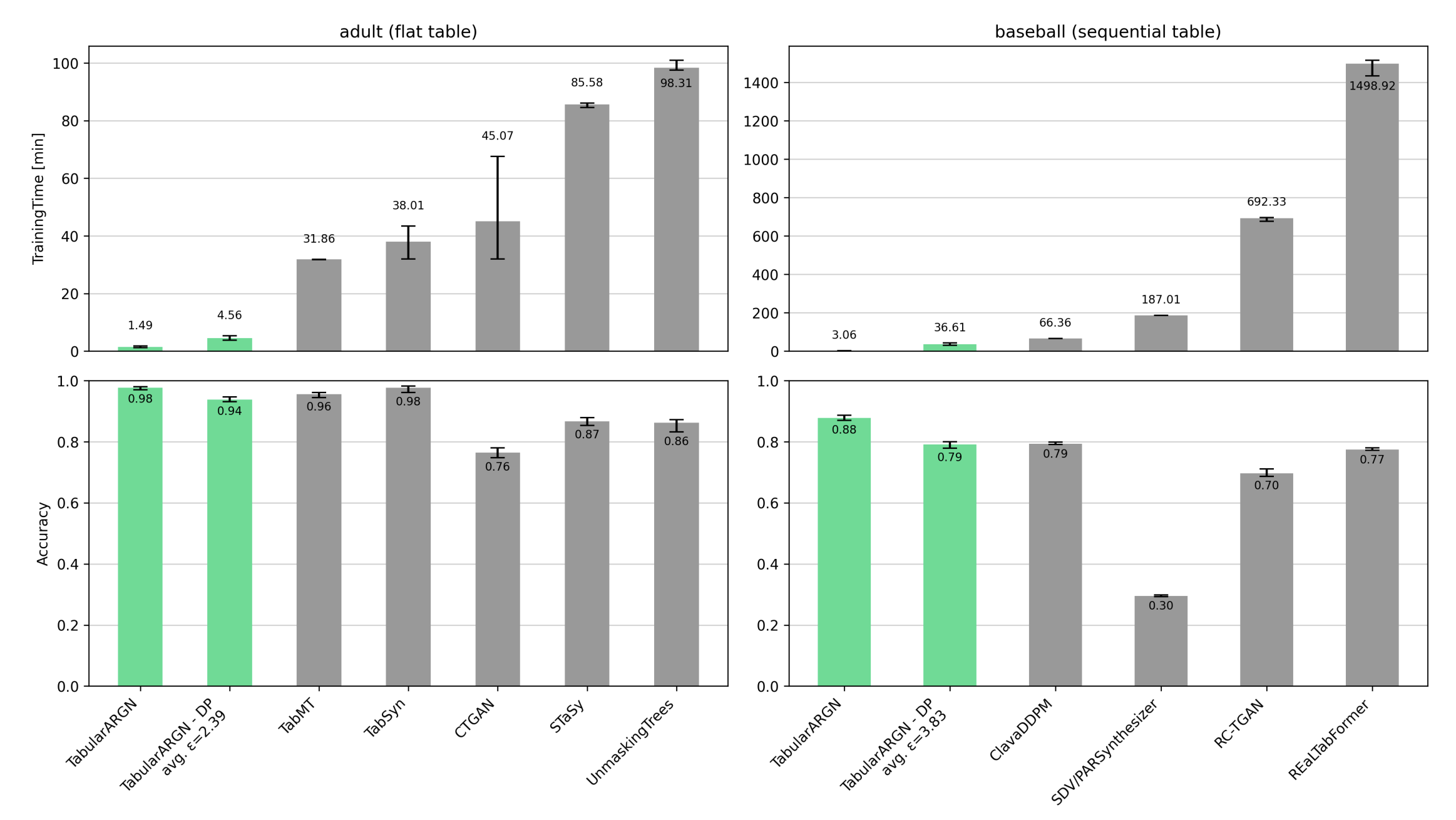
Tabular models within the SDK are built on TabularARGN (arXiv:2501.12012), which achieves best-in-class synthetic data quality while being 1–2 orders of magnitude more efficient than comparable models. This efficiency enables the training and generation of millions of synthetic records within minutes, even on CPU environments.
Language Models
The default language model is a basic, non-pre-trained LSTM (LSTMFromScratch-3m), particularly effective for textual data with limited scope (short lengths, narrow variety) and sufficient training samples.
Alternatively, any pre-trained SLM available via the Hugging Face Hub can be selected to be then fine-tuned on the provided training data. These models start out already with a general world knowledge, and then adapt to the training data for generating high-fidelity synthetic samples even in sparse data domains. The final performance will once again largely depend on the chosen model configurations.
In either case, a modern GPU is highly recommended when working with language models.
Installation
Use pip (or better uv pip) to install the official mostlyai package via PyPI. Python 3.10 or higher is required.
It is highly recommended to install the package within a dedicated virtual environment using uv.
Setup of uv on Unix / macOS
# Install uv if you don't have it yet
curl -Ls https://astral.sh/uv/install.sh | bash
# Create and activate a Python 3.12 environment with uv
mkdir ~/synthetic-data-sdk; cd ~/synthetic-data-sdk
uv venv -p 3.12
# Activate virtual environment
source .venv/bin/activate
Setup of uv on Windows
# Install uv if you don't have it yet
irm https://astral.sh/uv/install.ps1 | iex
# Create and activate a Python 3.12 environment with uv
mkdir ~/synthetic-data-sdk; cd ~/synthetic-data-sdk
uv venv -p 3.12
# Activate virtual environment
.venv\Scripts\activate
Run Jupyter Lab session via uv
# Optionally launch jupyter session after SDK installation
uv run --with jupyter jupyter lab
CLIENT mode
This is a light-weight installation for using the SDK in CLIENT mode only. It communicates to a MOSTLY AI platform to perform requested tasks. See e.g. app.mostly.ai for a free-to-use hosted version.
uv pip install -U mostlyai
CLIENT + LOCAL mode
This is a full installation for using the SDK in both CLIENT and LOCAL mode. It includes all dependencies, incl. PyTorch, for training and generating synthetic data locally.
# for CPU on macOS
uv pip install -U 'mostlyai[local]'
# for CPU on Linux
uv pip install -U 'mostlyai[local-cpu]' --extra-index-url https://download.pytorch.org/whl/cpu
# for GPU on Linux
uv pip install -U 'mostlyai[local-gpu]'
Note for Google Colab users: Installing any of the local extras (
mostlyai[local],mostlyai[local-cpu], ormostlyai[local-gpu]) will downgrade Numpy from 2.0 to Numpy 1.26, due to Opacus dependency. You'll need to restart the runtime after installation for the changes to take effect.
Add any of the following extras for further data connectors support in LOCAL mode: databricks, googlebigquery, hive, mssql, mysql, oracle, postgres, snowflake. E.g.
uv pip install -U 'mostlyai[local, databricks, snowflake]'
Citation
Please consider citing our project if you find it useful:
@software{mostlyai,
author = {{MOSTLY AI}},
title = {{MOSTLY AI SDK}},
url = {https://github.com/mostly-ai/mostlyai},
year = {2025}
}