
Eventual Shop

A state-of-the-art distributed system using Reactive DDD as uncertainty modeling, Event Storming as subdomain decomposition, Event Sourcing as an eventual persistence mechanism, CQRS, Async Project…
Miscellaneous
About • The Solution Architecture • Research • Running • Tech Stack
| Service | Command Stack | Query Stack |
|---|---|---|
| Account | ||
| Communication | ||
| Identity | ||
| Order | ||
| Catalog | ||
| Warehouse | ||
| Shopping Cart | ||
| Payment |
:construction: Work in Progress (WIP)
:bulb: About
The main objective of this cloud-native project is to represent the state-of-the-art of a distributed, reliable, and highly scalable system by interpreting the most relevant principles of Reactive Domain Driven Design.
Domain-Driven Design can aid with managing uncertainty through the use of good modeling.
-- Vaughn Vernon
Scalability and Resilience require low coupling and high cohesion, principles strongly linked to the proper understanding of the business through well-defined boundaries, combined with a healthy and efficient integration strategy such as Event-driven Architecture (EDA).
The Event Storming workshop provides a practical approach to subdomain decomposition, using Pivotal Events to correlate business capabilities across Bounded Contexts while promoting reactive integration between Aggregates.
The reactive integration between Bounded Contexts configures an Event-driven Architecture (EDA) where Commands are acknowledged and sent to the Bus by the Web API (BFF/Gateway) while Events are broadcasted to the Query side and/or other Aggregates.
Independence, as the main characteristic of a Microservice, can only be found in a Bounded Context.
The Event Sourcing is a proprietary implementation that, in addition to being naturally auditable and data-driven, represents the most efficient persistence mechanism ever. An eventual state transition Aggregate design is essential at this point. The Event Store comprises EF Core (ORM) + MSSQL (Database).
State transitions are an important part of our problem space and should be modeled within our domain.
-- Greg Young
Projections are asynchronously denormalized and stored on a NoSQL Database(MongoDB); Nested documents should be avoided here; Each projection has its index and fits perfectly into a view or component, mitigating unnecessary data traffic and making the reading side as efficient as possible.
The splitting between Command and Query stacks occurs logically through the CQRS pattern and fiscally via a Microservices architecture. Each stack is an individual deployable unit with its database, and the data flows from Command to Query stack via Domain and/or Summary events.
As a domain-centric approach, Clean Architecture provides the appropriate isolation between the Core (Application + Domain) and "times many" Infrastructure concerns.
:star: Give a Star!
Support this research by giving it a star. Thanks!
:classical_building: The Solution Architecture

Fig. 1: Falcão Jr., Antônio. An EDA solution architecture.
:mag_right: Research
Agnostic Obsession
Agnostic Obsession
Agnostic obsession is a design approach that focuses on creating software unrelated to any specific domain, application, or technology. Some strategies adopted in this project are related to particular principles, such as the domain-centric to support the business (Reactive DDD and Clean Architecture); Event Sourcing + object-relational mapping (ORM) for persistence mechanism; Containers for immutable environments; and Kubernetes (K8s) for cloud deployment.
The domain-centric approach is a design pattern that separates the core business logic of an application from other concerns, such as the user interface or infrastructure, making it easier to maintain and extend the application, as the core domain is isolated from other system components. Additionally, the ability to move the core domain to different applications while keeping the essence of the business can be helpful for organizations that need to support multiple applications or platforms.
A key aspect of agnostic obsession is event-sourcing and object-relational mapping (ORM) as a persistence mechanism. Event sourcing involves storing the history of events occurring within a system rather than the system's current state, avoiding advanced database capabilities such as Joins, Triggers, Procedures, and more. On the other hand, ORM is a technique that maps objects in a program to data stored in a database, making it easier and more abstract to manage data.
Another essential aspect of agnostic obsession is using containers to create immutable environments. Containers are a lightweight virtualization form that allows packaging an application and its dependencies into a single, self-contained unit, making it easy to deploy and run the application in any environment without worrying about the underlying infrastructure or platform.
Finally, agnostic obsession often involves using Kubernetes (K8s) for cloud deployment. K8s is an open-source platform for managing and deploying containerized applications. It is widely used in the industry and supported by most cloud providers, making it a natural choice for agnostic obsession.
In summary, agnostic obsession is a powerful approach that allows for creating highly flexible and adaptable software that can be easily moved and deployed in different environments. Using event-sourcing, ORM, Containers, and K8s, it is possible to build resilient, scalable, and easy-to-maintain systems.
Reactive Domain Driven Design
Reactive Domain Driven Design
Reactive DDD aims to create software that is responsive, resilient, and scalable, by applying the principles of reactive programming to domain-driven design. This involves using asynchronous and non-blocking communication between the different components of the system, and using events and streams to model the domain concepts and relationships.
I have been seeing, at least in my world, a trend towards reactive systems. Not just reactive within a microservice, but building entire systems that are reactive. In DDD, reactive behavior is also happening within the bounded context. Being reactive isn't entirely new, and Eric Evans was far ahead of the industry when he introduced eventing. Using domain events means we have to react to events that happened in the past, and bring our system into harmony.
Vernon, Vaughn. "Modeling Uncertainty with Reactive DDD", www.infoq.com, last edited on 29 Set 2018
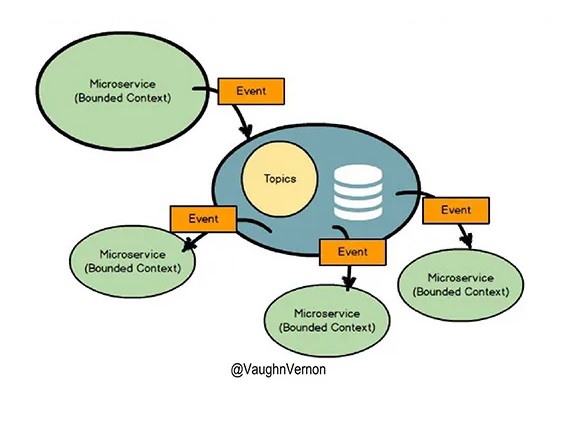
Fig. 2: Vernon, V. (2018), "Modeling Uncertainty with Reactive DDD", Reactive Systems, www.infoq.com
Reactive Process
Each domain entity is responsible for tracking its state, based on the commands it receives. By following good DDD practices, the state can be safely tracked based on these commands, and using event sourcing to persist the state change events.
This is where we want to be. When everything is happening asynchronously everywhere, what happens? That brings us to uncertainty.
If there is any possibility of any message being out of order, you have to plan for all of them being out of order.
Each entity is also responsible for knowing how to handle any potential uncertainty, according to decisions made by domain experts. For example, if a duplicate event is received, the aggregate will know that it has already seen it, and can decide how to respond.
Vernon, Vaughn. "Modeling Uncertainty with Reactive DDD", www.infoq.com, last edited on 29 Set 2018
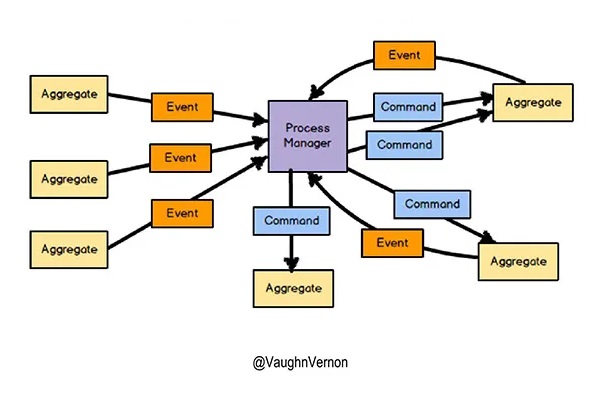
Fig. 3: Vernon, V. (2018), "Modeling Uncertainty with Reactive DDD", Process Manager, www.infoq.com
Messaging - Making good use of Context Mapping
When using asynchronous messaging to integrate, much can be accomplished by a client Bounded Context subscribing to the Domain Events published by your own or another Bounded Context. Using messaging is one of the most robust forms of integration because you remove much of the temporal coupling associated with blocking forms such as RPC and REST. Since you already anticipate the latency of message exchange, you tend to build more robust systems because you never expect immediate results.
Typically an Aggregate in one Bounded Context publishes a Domain Event, which could be consumed by any number of interested parties. When a subscribing Bounded Context receives the Domain Event, some action will be taken based on its type and value. Normally it will cause a new Aggregate to be created or an existing Aggregate to be modified in the consuming Bounded Context.
Vernon, V. (2016) Domain-Driven Design Distilled, 1st ed. New York: Addison-Wesley Professional, p65-67.
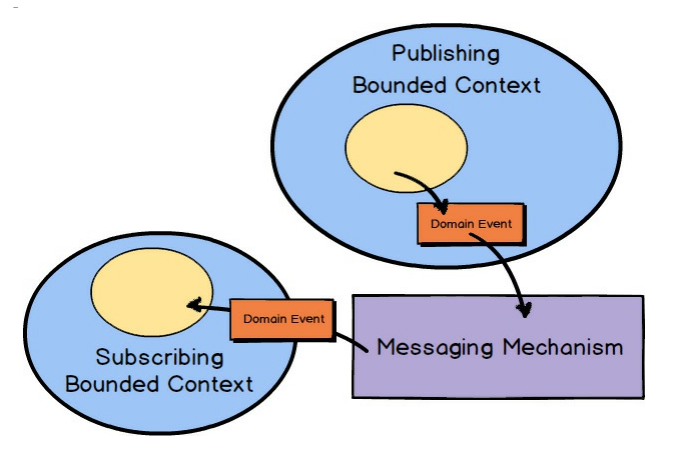
Fig. 4: Vernon, V. (2016), Messaging from Domain-Driven Design Distilled, 1st ed, p65.
Domain Driven Design (DDD)
Domain-Driven Design is an approach to software development that centers the development on programming a domain model that has a rich understanding of the processes and rules of a domain. The name comes from a 2003 book by Eric Evans that describes the approach through a catalog of patterns. Since then a community of practitioners have further developed the ideas, spawning various other books and training courses. The approach is particularly suited to complex domains, where a lot of often-messy logic needs to be organized.
Fowler, Martin. "DomainDrivenDesign", martinfowler.com, last edited on 22 April 2020
Bounded Context
Basically, the idea behind bounded context is to put a clear delineation between one model and another model. This delineation and boundary that's put around a domain model, makes the model that is inside the boundary very explicit with very clear meaning as to the concepts, the elements of the model, and the way that the team, including domain experts, think about the model.
You'll find a ubiquitous language that is spoken by the team and that is modeled in software by the team. In scenarios and discussions where somebody says, for example, "product," they know in that context exactly what product means. In another context, product can have a different meaning, one that was defined by another team. The product may share identities across bounded contexts, but, generally speaking, the product in another context has at least a slightly different meaning, and possibly even a vastly different meaning.
Vernon, Vaughn. "Modeling Uncertainty with Reactive DDD", www.infoq.com, last edited on 29 Set 2018
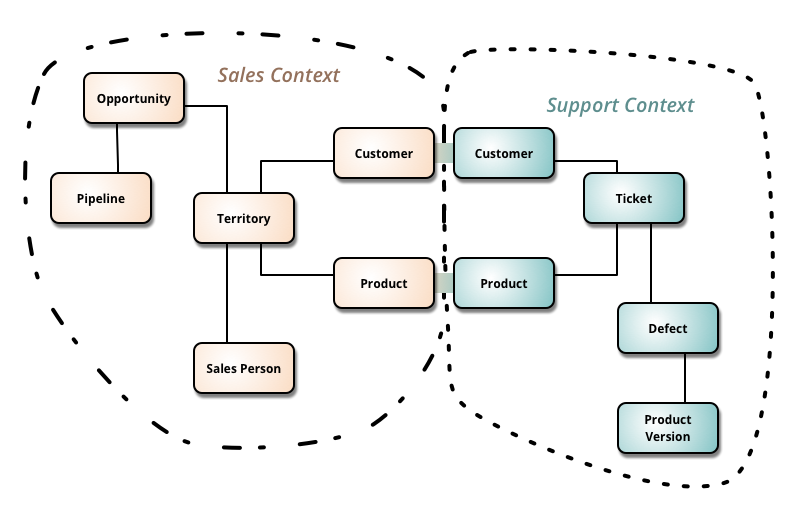
Fig. 5: Martin, Fowler. BoundedContext
First, a Bounded Context is a semantic contextual boundary. This means that within the boundary each component of the software model has a specific meaning and does specific things. The components inside a Bounded Context are context specific and semantically motivated. That’s simple enough.
When you are just getting started in your software modeling efforts, your Bounded Context is somewhat conceptual. You could think of it as part of your problem space. However, as your model starts to take on deeper meaning and clarity, your Bounded Context will quickly transition to your solution space , with your software model being reflected as project source code. Remember that a Bounded Context is where a model is implemented, and you will have separate software artifacts for each Bounded Context.
Vernon, V. (2016). "Strategic Design with Bounded Contexts and the Ubiquitous Language", Domain-Driven Design Distilled, 1st ed. New York: Addison-Wesley Professional.
Explicitly define the context within which a model applies. Explicitly set boundaries in terms of team organization, usage within specific parts of the application, and physical manifestations such as code bases and database schemas. Apply Continuous Integration to keep model concepts and terms strictly consistent within these bounds, but don’t be distracted or confused by issues outside. Standardize a single development process within the context, which need not be used elsewhere.
Evans, Eric. (2015). "Bounded Context", Domain-Driven Design Reference
Aggregate
I think a model is a set of related concepts that can be applied to solve a problem. -- Eric Evans
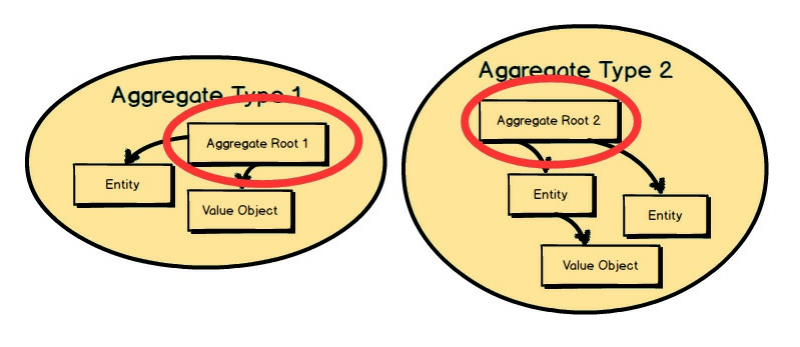
Fig. 6: Vernon, V. (2016), Aggregates from Domain-Driven Design Distilled, 1st ed, p78.
Each Aggregate forms a transactional consistency boundary. This means that within a single Aggregate, all composed parts must be consistent, according to business rules, when the controlling transaction is committed to the database. This doesn't necessarily mean that you are not supposed to compose other elements within an Aggregate that don't need to be consistent after a transaction. After all, an Aggregate also models a conceptual whole. But you should be first and foremost concerned with transactional consistency. The outer boundary drawn around Aggregate Type 1 and Aggregate Type 2 represents a separate transaction that will be in control of atomically persisting each object cluster.
Vernon, V. (2016) Domain-Driven Design Distilled, 1st ed. New York: Addison-Wesley Professional, p78.
Aggregate is a pattern in Domain-Driven Design. A DDD aggregate is a cluster of domain objects that can be treated as a single unit. An example may be an order and its line-items, these will be separate objects, but it's useful to treat the order (together with its line items) as a single aggregate.
Fowler, Martin. "DDD_Aggregate", martinfowler.com, last edited on 08 Jun 2015
Event Sourcing
Event Sourcing
Note. Greg Young takes the next steps beyond the DDD principles and best practices introduced by Eric Evans in Domain-Driven Design: Tackling Complexity in the Heart of Software, using DDD with Command-Query Responsibility Segregation (CQRS) and event sourcing to simplify construction, decentralize decision-making, and make system development more flexible and responsive. Adapted from "Event Centric: Finding Simplicity in Complex Systems" by Y. Greg, 2012.
Instead of storing just the current state of the data in a domain, use an append-only store to record the full series of actions taken on that data. The store acts as the system of record and can be used to materialize the domain objects. This can simplify tasks in complex domains, by avoiding the need to synchronize the data model and the business domain, while improving performance, scalability, and responsiveness. It can also provide consistency for transactional data, and maintain full audit trails and history that can enable compensating actions.
"Event Sourcing pattern" MSDN, Microsoft Docs, last edited on 23 Jun 2017
We can query an application's state to find out the current state of the world, and this answers many questions. However there are times when we don't just want to see where we are, we also want to know how we got there.
Event Sourcing ensures that all changes to application state are stored as a sequence of events. Not just can we query these events, we can also use the event log to reconstruct past states, and as a foundation to automatically adjust the state to cope with retroactive changes.
Fowler, Martin. "Eventsourcing", martinfowler.com, last edited on 12 Dec 2005
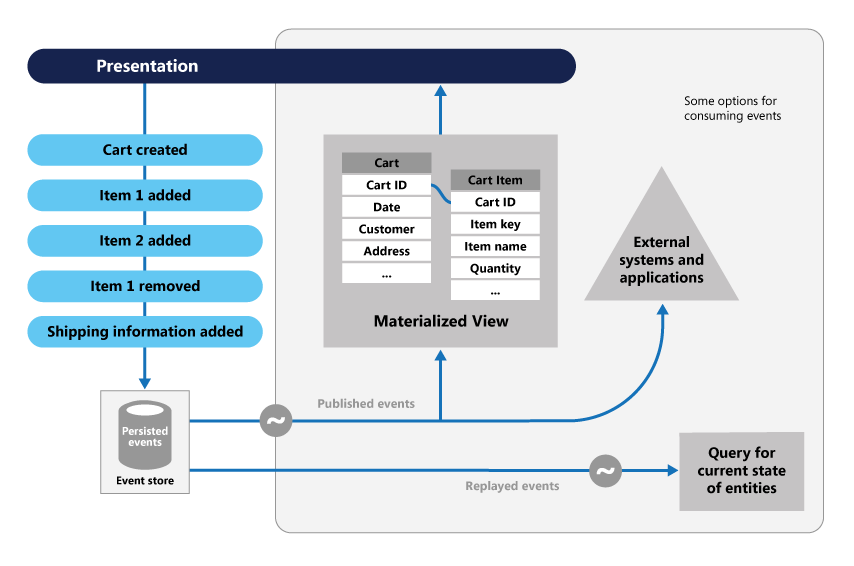
Fig. 7: MSDN. Event Sourcing pattern
Updating entities
To update an entity’s state we use commands from the outside and events on the inside:
Commands: The state of the entity can be changed only by sending commands to it. The commands are the "external" API of an entity. Commands request state changes. The current state may reject the command, or it may accept it producing zero, one or many events (depending on the command and the current state).
Events: The events represent changes of the entity’s state and are the only way to change it. The entity creates events from commands. Events are an internal mechanism for the entity to mutate the state, other parties can’t send events. Other parts of the application may listen to the created events. Summing up, events are facts.
The events are persisted to the datastore, while the entity state is kept in memory. In case of a restart the latest state gets rebuilt by replaying the events from the Event Journal.
Pattern
want to learn event sourcing?
f(state, event) => state-- @gregyoung
![]()
Fig. 8: Battermann, Leif. 12 Things You Should Know About Event Sourcing
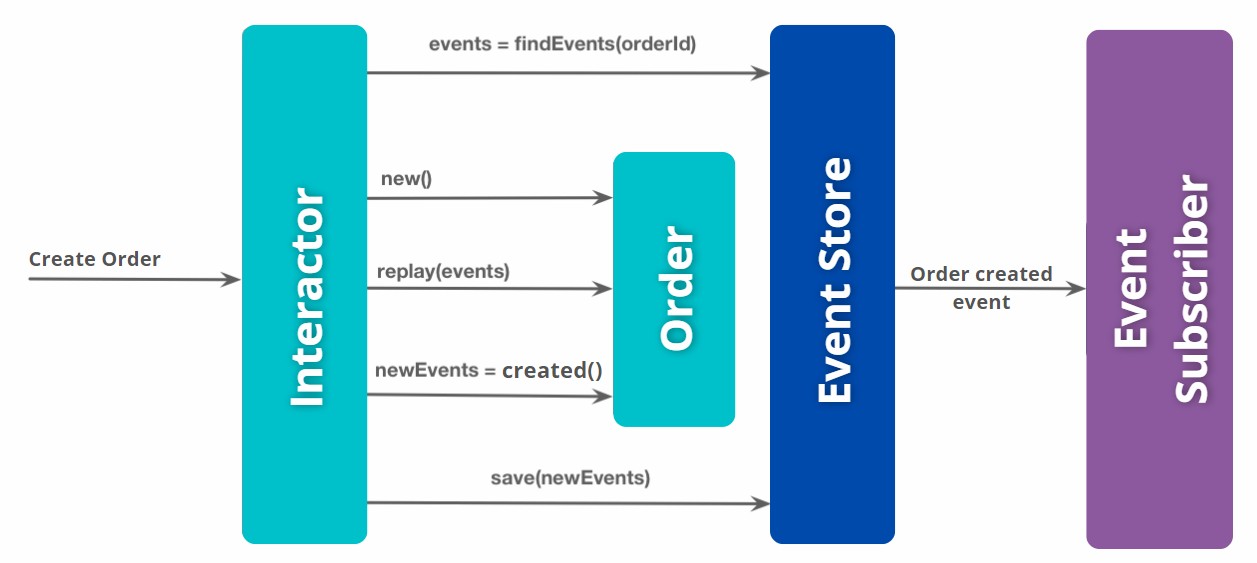
Fig. 9: Eventuate. Event Sourcing
The mantra of event sourcing and cover the four steps in slightly more details:
1 - A command is received by an aggregate.
2 - The aggregate checks to see if the command can be applied.
3 - If the command can be applied:
1 - The aggregate creates at least one event;
2 - The aggregate changes state based on the event details;
3 - As a unit:
3.1 - The event is persisted in the store;
3.2 - The event is published in the exchange.
4 - If the command cannot be applied:
1 - If necessary, the aggregate creates a failure event;
2 - The aggregate changes state based on the failure event;
3 - As a unit:
3.1 - The failure event is persisted in the store;
3.2 - The failure event is published in the exchange.
State transition during events applying:
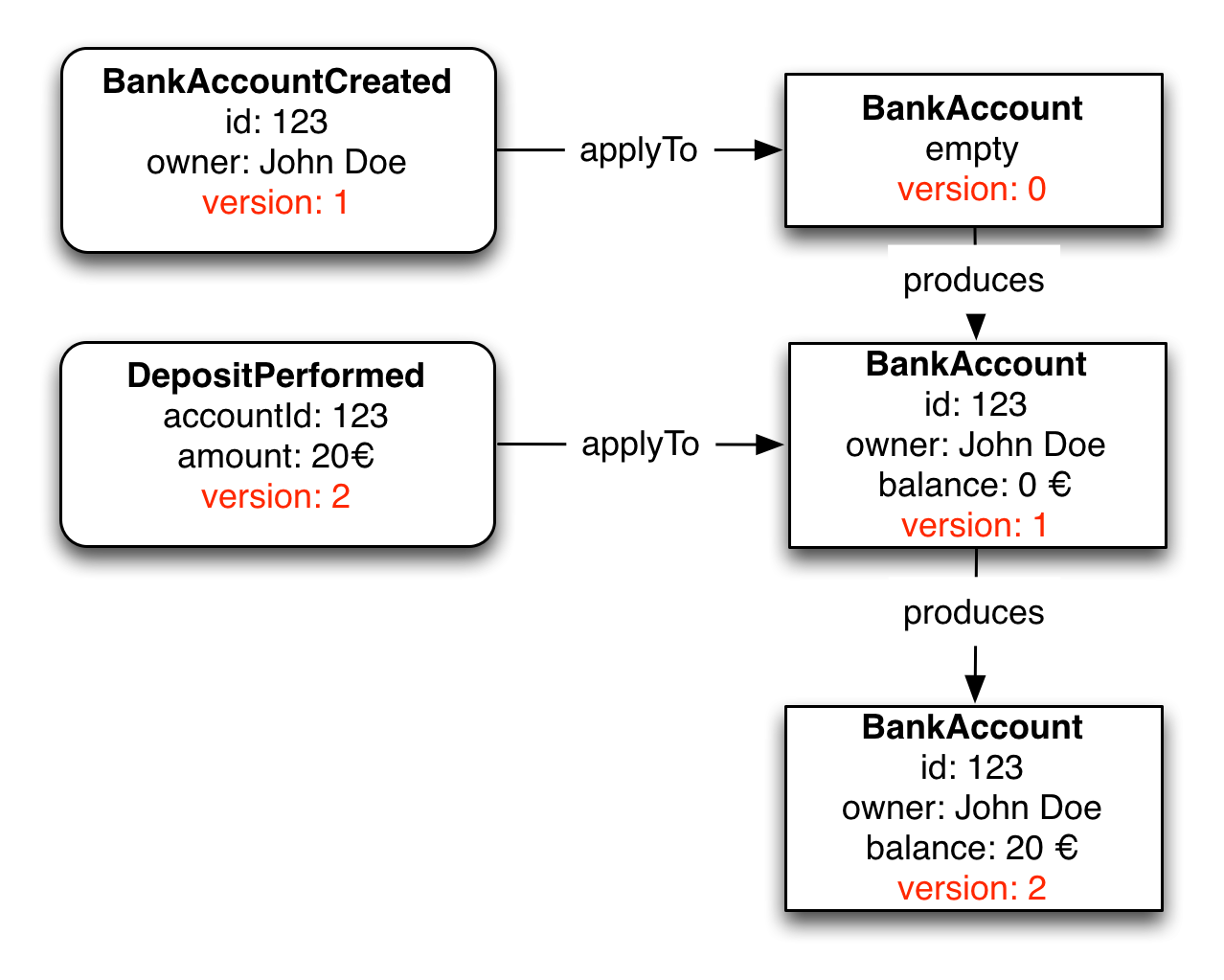
Fig. 10: Reitzammer, Benjamin & Seitz, Johannes. Event Sourcingin practice
Event Store
So, Event Sourcing is the persistence mechanism where each state transition for a given entity is represented as a domain event that gets persisted to an event database (event store). When the entity state mutates, a new event is produced and saved. When we need to restore the entity state, we read all the events for that entity and apply each event to change the state, reaching the correct final state of the entity when all available events are read and applied.
Zimarev, Alexey. "What is Event Sourcing?", Event Store blog, last edited on 03 June 2020
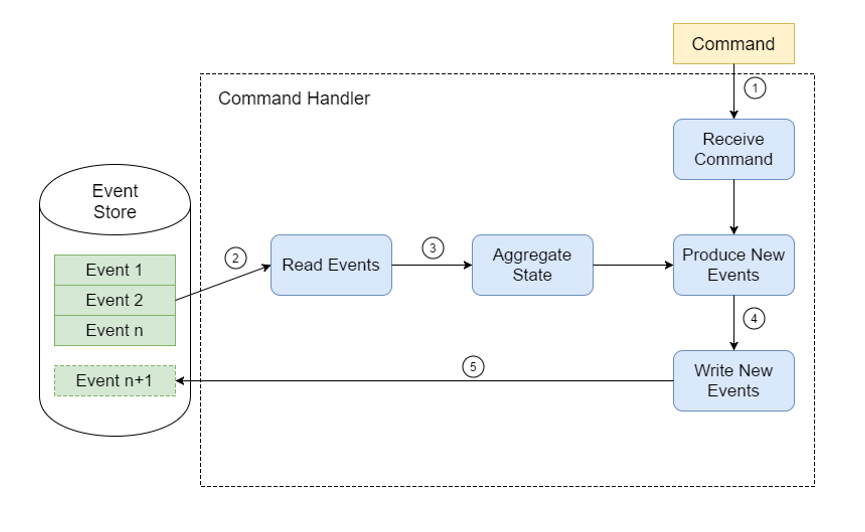
Fig. 11: Shilkov, Mikhail. Event Sourcing and IO Complexity
The following picture shows the difference between approaches:
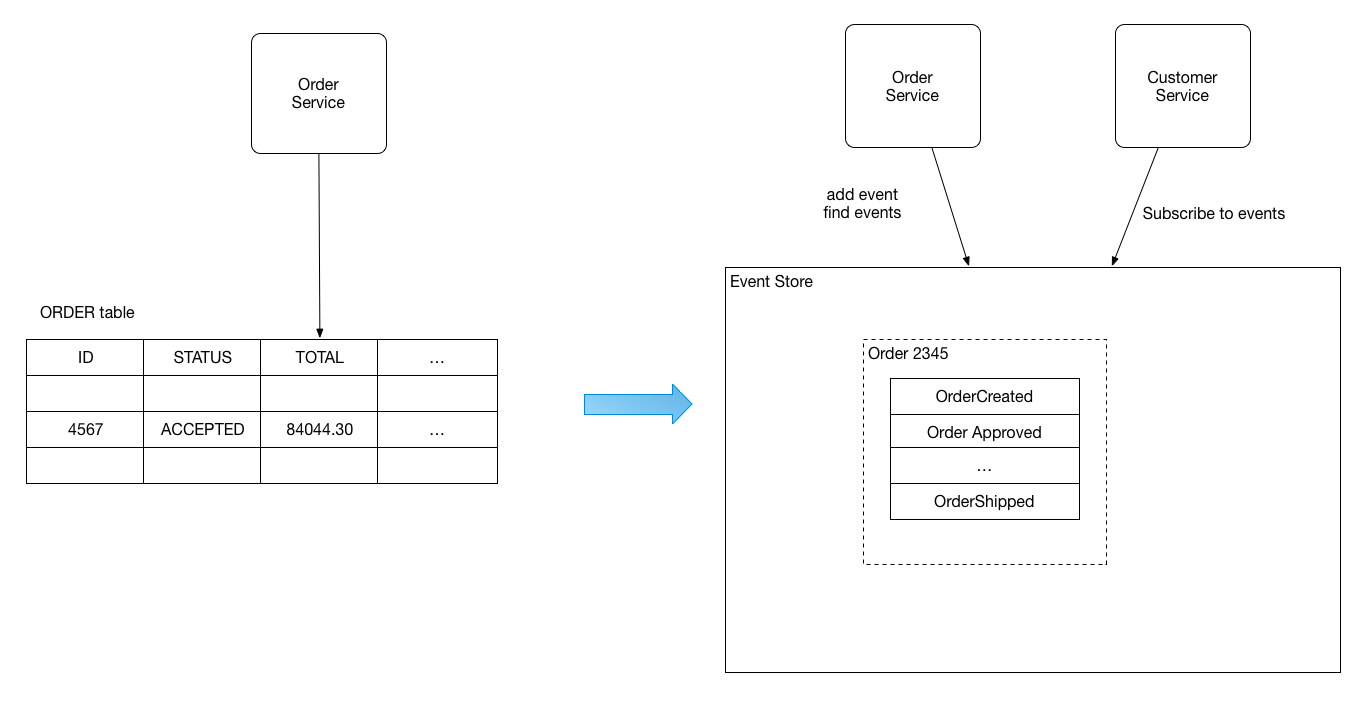 Fig. 12: Richardson, Chris. Pattern: Event sourcing
Fig. 12: Richardson, Chris. Pattern: Event sourcing
Exemplifying
Store Event
CREATE TABLE [Events] (
[Version] bigint NOT NULL,
[AggregateId] uniqueidentifier NOT NULL,
[AggregateName] varchar(30) NOT NULL,
[DomainEventName] varchar(50) NOT NULL,
[DomainEvent] nvarchar(max) NOT NULL,
CONSTRAINT [PK_Events] PRIMARY KEY ([Version], [AggregateId])
);

{
"$type": "Contracts.Services.Account.DomainEvent+AccountCreated, Contracts",
"Id": "b7450a4c-5749-4131-830c-28dcfd7e5dea",
"FirstName": "Antônio Roque",
"LastName": "Falcão Júnior",
"Email": "arfj@edu.univali.br",
"Timestamp": "2022-08-31T19:27:41.7810008-03:00",
"CorrelationId": "b7450a4c-5749-4131-830c-28dcfd7e5dea"
}
Snapshot
CREATE TABLE [Snapshots] (
[AggregateVersion] bigint NOT NULL,
[AggregateId] uniqueidentifier NOT NULL,
[AggregateName] varchar(30) NOT NULL,
[AggregateState] nvarchar(max) NOT NULL,
CONSTRAINT [PK_Snapshots] PRIMARY KEY ([AggregateVersion], [AggregateId])
);

{
"CustomerId": "3fa85f64-5717-4562-b3fc-2c963f66afa6",
"Status": {
"Name": "Confirmed",
"Value": 2
},
"BillingAddress": null,
"ShippingAddress": null,
"Total": 0.0,
"TotalPayment": 0.0,
"AmountDue": 0.0,
"Items": [],
"PaymentMethods": [],
"Id": "de2ec981-24c1-4c27-abbb-dd50d99a1e16",
"IsDeleted": false
}
Snapshot
Once you understand how Event Sourcing works, the most common thought is: “What happens when you have a lot of Events? Won’t it be inefficient to fetch every event from the event stream and replay all of them to get to the current state?”. It might be. But to combat this, you can use snapshots in event sourcing to rehydrate aggregates. Snapshots give you a representation of your aggregates state at a point in time. You can then use this as a checkpoint and then only replay the events since the snapshot.
Snapshotting is an optimisation that reduces time spent on reading event from an event store. If for example a stream contains thousands of events, and we need to read all of them every time, then the time the system takes to handle a command will be noticeable. What we can do instead is to create a snapshot of the aggregate state and save it. Then before a command is handled we can load the latest snapshot and only new events since the snapshot was created.
Gunia, Kacper. "Event Sourcing: Snapshotting", domaincentric.net, last edited on 5 Jun 2020
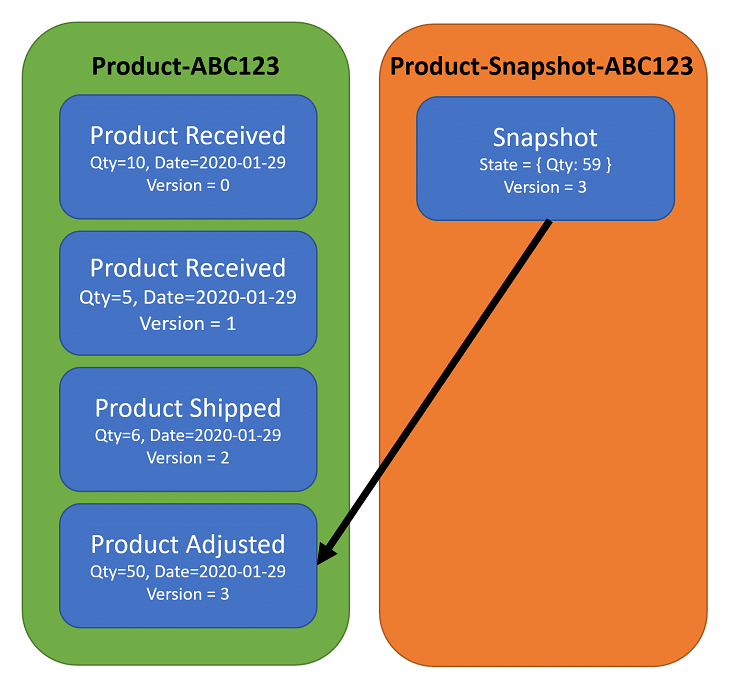
Fig. 13: Comartin, Derek. Snapshots in Event Sourcing for Rehydrating Aggregates
Snapshot stream:
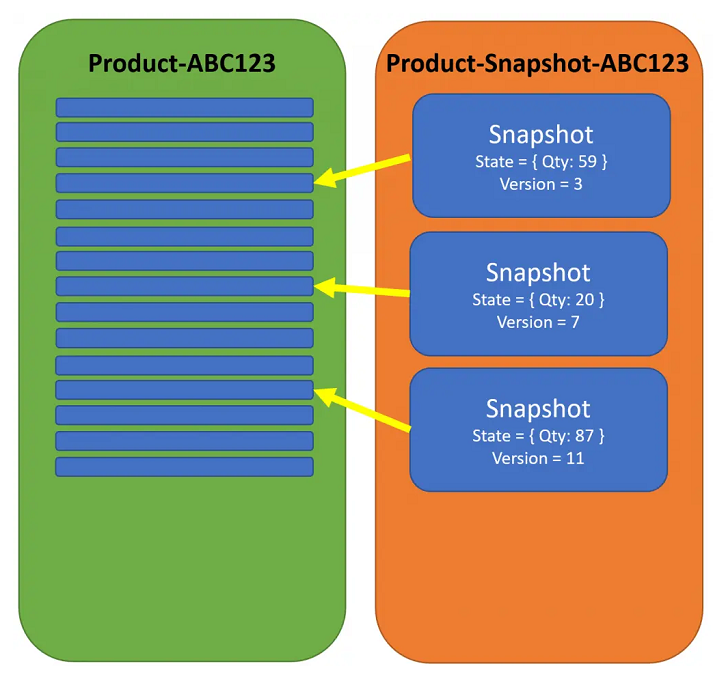
Fig. 14: Comartin, Derek. Snapshots in Event Sourcing for Rehydrating Aggregates
Event-Driven Architecture (EDA)
Event-Driven Architecture (EDA)
Event-driven architecture (EDA) is a software architecture paradigm promoting the production, detection, consumption of, and reaction to events. An event can be defined as "a significant change in state".
"Event-driven architecture." Wikipedia, Wikimedia Foundation, last edited on 9 May 2021
Event-driven architecture refers to a system of loosely coupled microservices that exchange information between each other through the production and consumption of events. An event-driven system enables messages to be ingested into the event driven ecosystem and then broadcast out to whichever services are interested in receiving them.
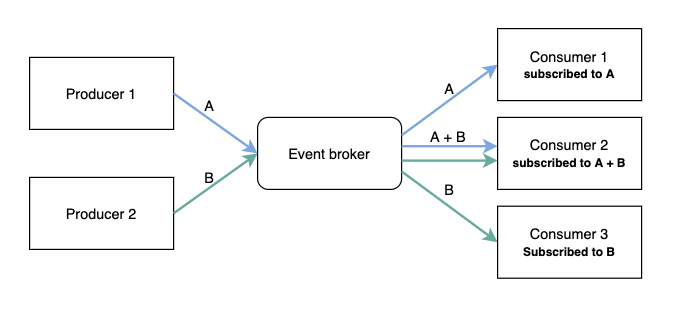
Topologies
To achieve complex responses, event-driven architectures consist of two main topologies: the mediator and the broker. The mediator topology is commonly used when you need to orchestrate multiple steps within an event through a central mediator, whereas the broker topology is used when you want to chain events and responses together directly without the need for a mediator. Because the architecture characteristics and implementation strategies differ between these two EDA topologies, it is important to understand each one to know which is best suited for your particular use case.
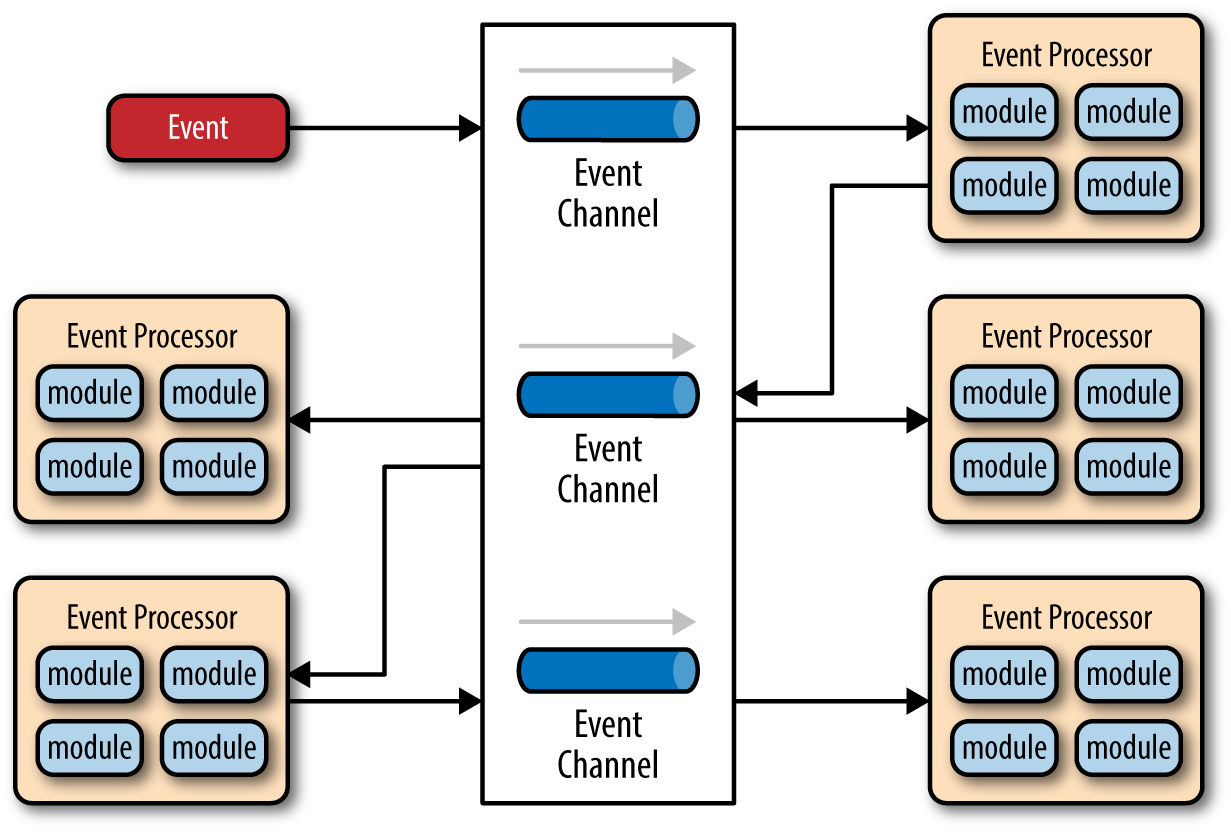
Broker Topology
The broker topology differs from the mediator topology in that there is no central event mediator; rather, the message flow is distributed across the event processor components in a chain-like fashion through a lightweight message broker (e.g., ActiveMQ, HornetQ, etc.). This topology is useful when you have a relatively simple event processing flow and you do not want (or need) central event orchestration.
There are two main types of architecture components within the broker topology: a broker component and an event processor component. The broker component can be centralized or federated and contains all of the event channels that are used within the event flow. The event channels contained within the broker component can be message queues, message topics, or a combination of both.
Richards, Mark. "Broker Topology." Software Architecture Patterns by Mark Richards, O'Reilly
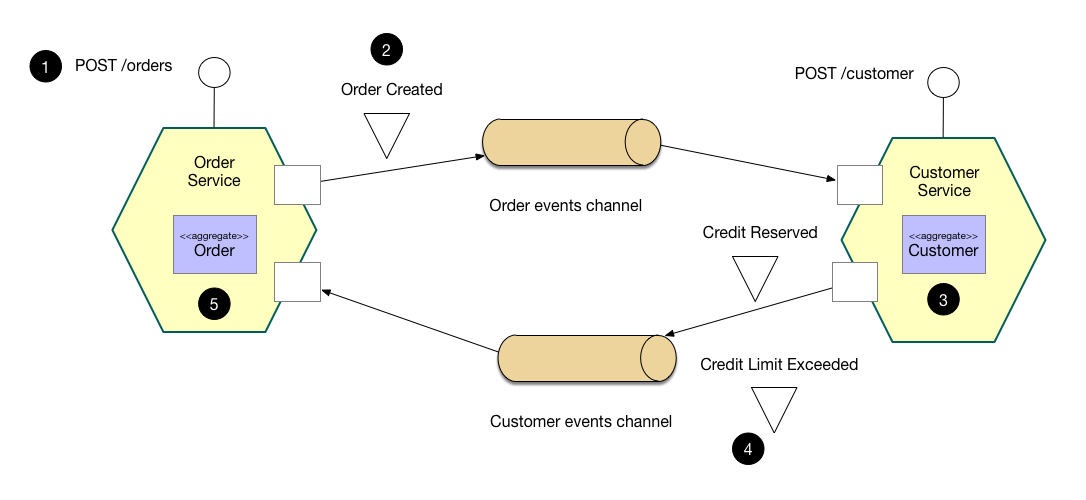
Choreography-based SAGA
In a choreography-based saga, the saga participants collaborate by exchanging events. Each step of a choreography-based saga updates the database (e.g. an aggregate) and publishes a domain event. The first step of a saga is initiated by a command that’s invoked by an external request, such an HTTP POST. Each subsequent step is triggered by an event emitted by a previous step.
Orchestration vs Choreography
SAGA - A long story about past events over a long period of time.
Orchestration entails actively controlling all elements and interactions like a conductor directs the musicians of an orchestra, while choreography entails establishing a pattern or routine that microservices follow as the music plays, without requiring supervision and instructions.
Schabowsky, Jonathan. "The Benefits of Choreography", solace.com, last edited on 16 Nov 2019
Orchestration
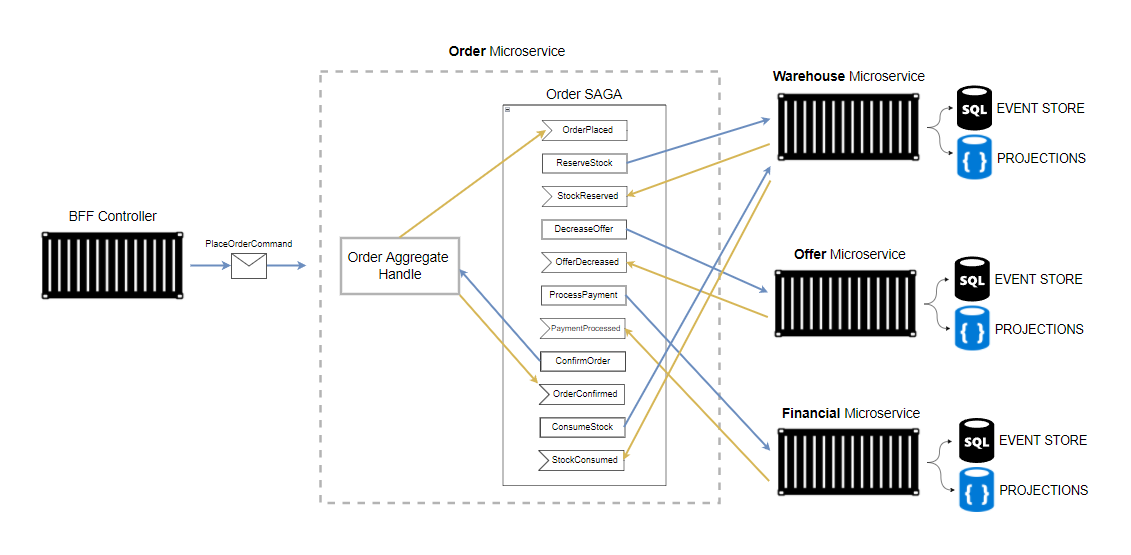
Fig. 18: Falcão, Antônio. "Order orchestration-based saga".
Benefits & drawbacks of Orchestration
- Centralized logic: this can be good and bad;
- High coupling: Need to know about the capability of other services;
- Easier to understand the workflow since its defined in a central location;
- Full control over the workflow steps via commands;
- Point of failure;
- Easier to debug and test.
Choreography
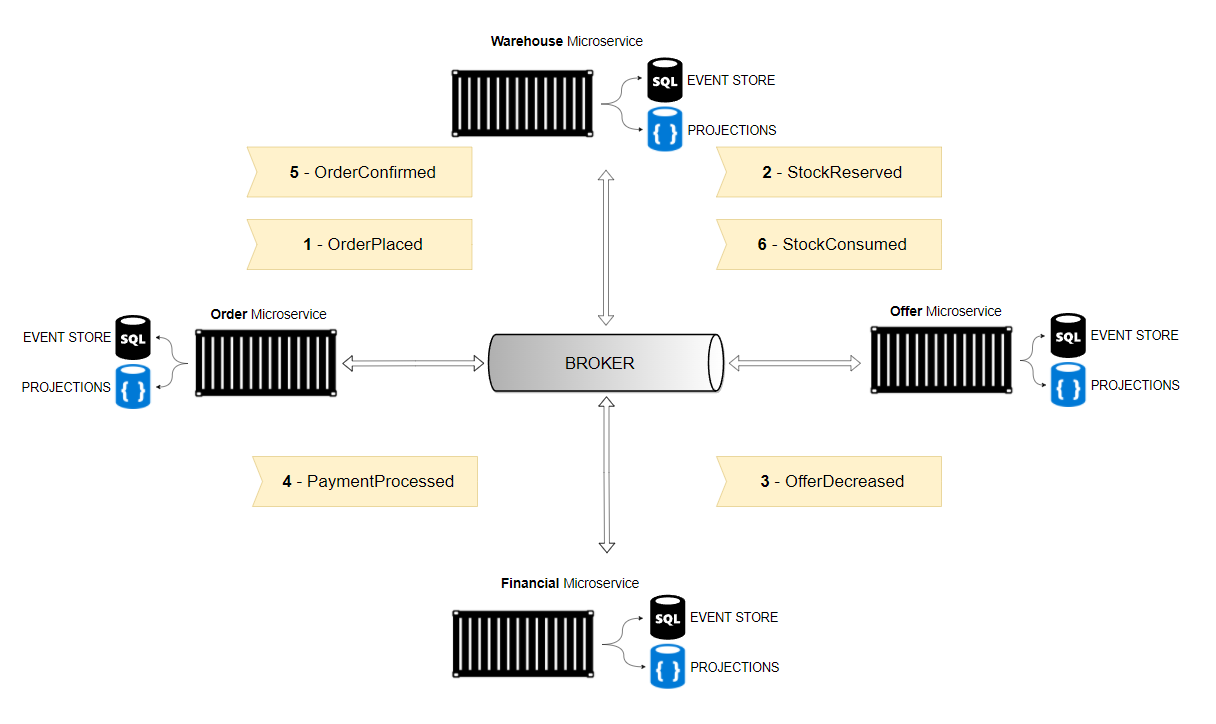
Fig. 19: Falcão, Antônio. "Order choreography-based saga".
Benefits & drawbacks of Choreography
- No centralized logic: this can be good and bad;
- Low coupling: Clear separation of concerns;
- Better performance: Fewer messages to handle;
- Useful for small/simple workflows;
- Difficult to conceptualize if a lot of services are involved;
- Harder to debug & test if a lot of services are involved.
EDA & Microservices Architecture
The following table shows how EDA and Microservices architectural styles compliment each other:
| EDA | Microservices Architecture |
|---|---|
| Loose coupling between components/services | Bounded context which provides separation of concerns |
| Ability to scale individual components | Independently deployable & scalable |
| Processing components can be developed independent of each other | Support for polyglot programming |
| High cloud affinity | Cloud native |
| Asynchronous nature. As well as ability to throttle workload | Elastic scalability |
| Fault Tolerance and better resiliency | Good observability to detect failures quickly |
| Ability to build processing pipelines | Evolutionary in nature |
| Availability of sophisticated event brokers reduce code complexity | Set of standard reusable technical services often referred as MicroServices Chassis |
| A rich palate of proven Enterprise Integration Patterns | Provides a rich repository of reusable implementation patterns |
EDA vs SOA
Compared to SOA, the essence of an EDA is that the services involved communicate through the capture, propagation, processing and persistence of events. This resulting pattern of communicating through a dataflow is quite different from the SOA approach of requests and responses.
According to Mathew, here are some reasons why the EDA patterns can alleviate some of the challenges traditional SOA patterns bring:
| SOA | EDA | |
|---|---|---|
| Pull vs. Reactive | Client makes a request of a service and expects a response. It’s great for persisted, static data, but gets a little hard when data keeps changing. You have to poll to detect changes. | Subscription model pushes events to consumers. |
| Coupling | Client has to know details of the API and its location at runtime. | Producers have no knowledge of consumer which will ultimately receive the event. There is still some minimal coupling in terms names of queues/topics and event formats. |
| Service Availability | A service must be available at the time a request is made by a client even if you are doing an asynchronous response handling. | Events do not require a reply and are inherently asynchronous. Events can be persisted for future consumption. With a highly fault-tolerant broker, the event producer does not need to know whether the consumers are available. Thus, we achieve higher resilience to network and compute failure, and this allows event producers to avoid blocking. |
| Process Modification and Extension | Processing logic is a request-response API that is hardwired into a service endpoint (with or without service discovery). If the logic needs to change or be extended, or if new logic needs to be introduced, the definition (not contract) of the service must be updated. This introduces change management and regression risk. | Additional event producers and consumers can be added to a system without any explicit process definition. |
| Consistency Between Process Interaction and Internal State Management | State changes are managed based on requests. For example, a request to “withdraw money” mutates the state of an account. The distinct processes of a request, a change in state and its persistence in case of failure must be tied together transactionally. This often leads users to deploy expensive distributed transaction protocols like eXtended architecture (XA). | EDA provides better support for consistency between process interaction and persisted internal state transitions. This is done through the event sourcing pattern, where the communication protocol (the event) is also the persistence mechanism (the event log). The current state of a system can be built or rebuilt from the log of events. |
| Retaining the Exact State Transitions That Customers or Services Perform | In SOAs, data is typically “mutated in place” in a database. This is a lossy process where each state change loses the information about the state changes that happened previously. | EDAs are event sourced, meaning every state change is captured, providing a truthful journal of the exact state changes that every customer or every service made over time. This journal lets operators rewind time to view or replay previous events exactly as they happened. It is also important for analytics that review customer (or system) behavior to derive insight. |
| *Streaming Analytics | SOA is incapable of deriving analytics of data in flight. This requires the ability to detect a pattern from multiple state changes both temporally and spatially. | EDA is fully capable of detecting patterns across multiple event sources over many different types of time windows. Also, deriving analytics of data in flight is a means of continuous intelligence. |
| The Timing of Consistency and of Intelligence | Synchronous communication makes it a bit easier to create consistent state across services from a client’s perspective. Intelligence from the consistent state are derived eventually—that is, eventual intelligence and continuous consistency | Events, being asynchronous, mean that different services become consistent with one another only in eventuality: There is no control over the timeliness of the process of event propagation. |
Table 2: Mathew, Jerry. SOA vs. EDA: Is Not Life Simply a Series of Events?
EDA & Event-sourcing
Event sourcing a system means the treatment of events as the source of truth. In principle, until an event is made durable within the system, it cannot be processed any further. Just like an author’s story is not a story at all until it’s written, an event should not be projected, replayed, published or otherwise processed until it’s durable enough such as being persisted to a data store. Other designs where the event is secondary cannot rightfully claim to be event sourced but instead merely an event-logging system.
Combining EDA with the event-sourcing pattern is another increment of the system’s design because of the alignment of the EDA principle that events are the units of change and the event-sourcing principle that events should be stored first and foremost.
Comparison overview:
| Aspects | Event sourcing | EDA |
|---|---|---|
| Propose | Keeping history | Highly adaptable and scalable |
| Scope | Single application/system | Whole organisation/several apps |
| Storage | Central event store | Decentralised |
| Testing | Easier | Harder |
Table 3: Lorio, Pablo. Comparison overview, Event driven architectures vs event sourcing patterns
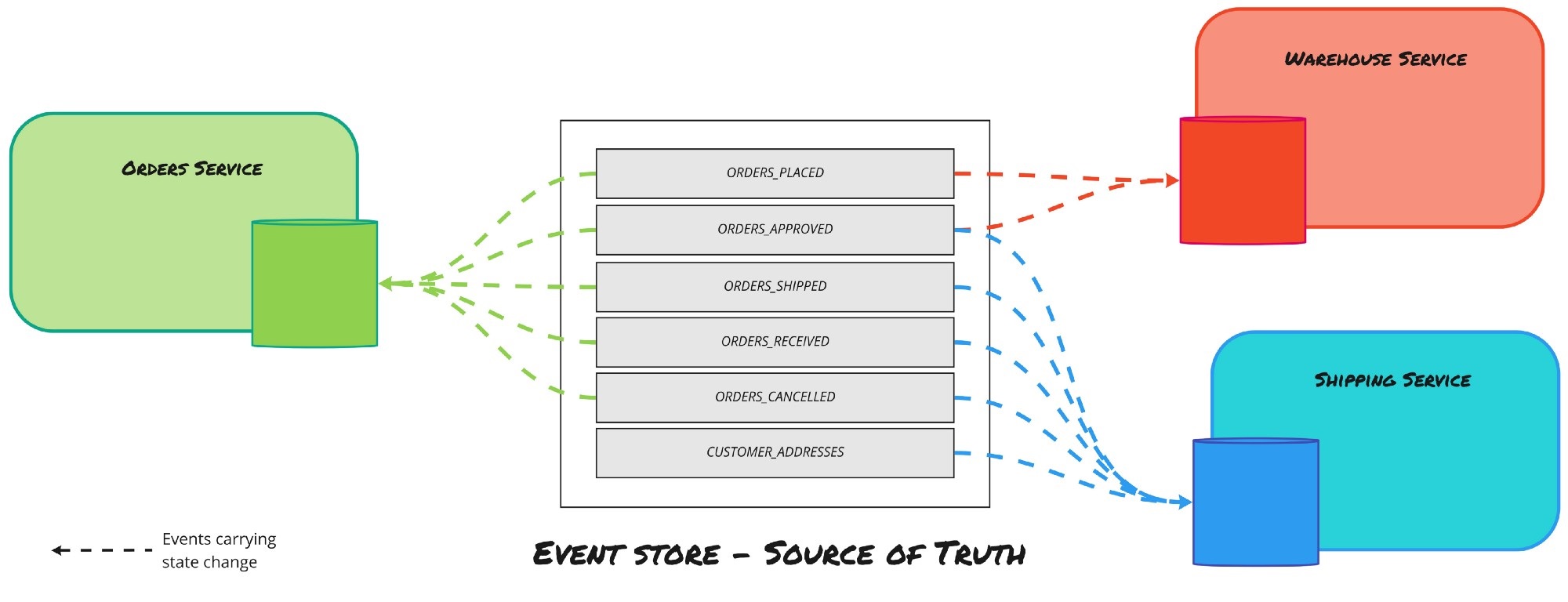
Fig. 20: Nowak, Aleksander. Understanding Event-Driven Design Patterns for Microservices
Microservices
Microservices
The term "Microservice Architecture" has sprung up over the last few years to describe a particular way of designing software applications as suites of independently deployable services. While there is no precise definition of this architectural style, there are certain common characteristics around organization around business capability, automated deployment, intelligence in the endpoints, and decentralized control of languages and data.
Fowler, Martin. "Microservices", martinfowler.com, last edited on 25 Mar 2014
Temporal Coupling and Autonomous Decisions
Temporal coupling is where you have a dependency on time where one service or one component cannot complete its operation until the other party is done with work. In order to get rid of this temporal coupling, what you can do is you can use events.
CQRS
CQRS
CQRS stands for Command and Query Responsibility Segregation, a pattern that separates read and update operations for a data store. Implementing CQRS in your application can maximize its performance, scalability, and security. The flexibility created by migrating to CQRS allows a system to better evolve over time and prevents update commands from causing merge conflicts at the domain level.
Benefits of CQRS include:
- Independent scaling. CQRS allows the read and write workloads to scale independently, and may result in fewer lock contentions.
- Optimized data schemas. The read side can use a schema that is optimized for queries, while the write side uses a schema that is optimized for updates.
- Security. It's easier to ensure that only the right domain entities are performing writes on the data.
- Separation of concerns. Segregating the read and write sides can result in models that are more maintainable and flexible. Most of the complex business logic goes into the write model. The > read model can be relatively simple.
- Simpler queries. By storing a materialized view in the read database, the application can avoid complex joins when querying.
"What is the CQRS pattern?" MSDN, Microsoft Docs, last edited on 2 Nov 2020
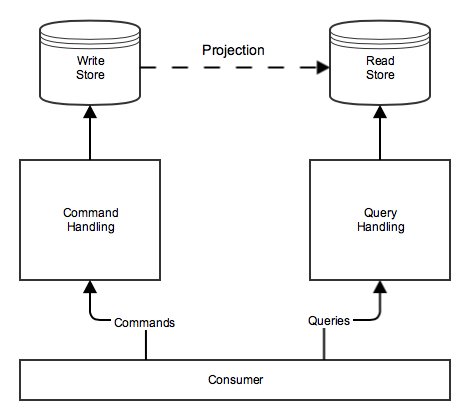
Fig. 21: Bürckel, Marco. Some thoughts on using CQRS without Event Sourcing
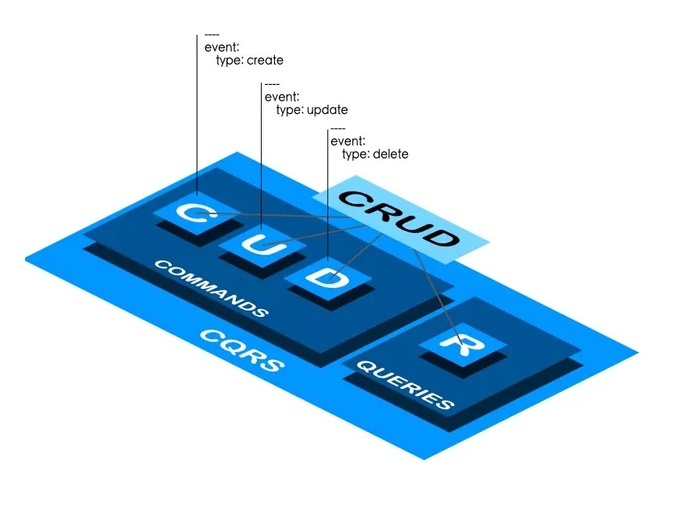 )
)
Fig. 22: Go, Jayson. From Monolith to Event-Driven: Finding Seams in Your Future Architecture
Command's pipeline
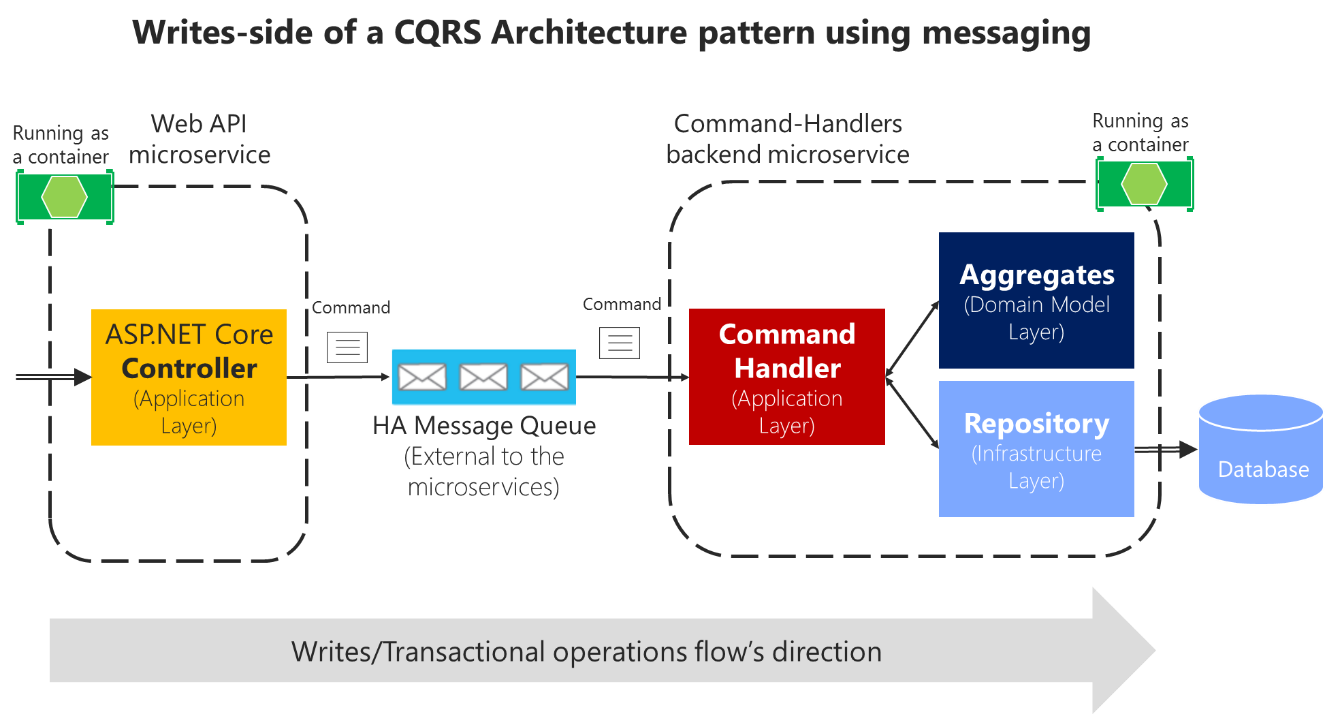
Fig. 23: MSDN. Use message queues (out-of-proc) in the command's pipeline
Projections
To cover this topic was prepared this presentation with some different strategies and ways to implement projections.

CQRS + Event Sourcing
CQRS and Event Sourcing have a symbiotic relationship. CQRS allows Event Sourcing to be used as the data storage mechanism for the domain.
Young Greg, 2012, CQRS and Event Sourcing, CQRS Documents by Greg Young, p50.
The CQRS pattern is often used along with the Event Sourcing pattern. CQRS-based systems use separate read and write data models, each tailored to relevant tasks and often located in physically separate stores. When used with the Event Sourcing pattern, the store of events is the write model, and is the official source of information. The read model of a CQRS-based system provides materialized views of the data, typically as highly denormalized views. These views are tailored to the interfaces and display requirements of the application, which helps to maximize both display and query performance.
"Event Sourcing and CQRS pattern" MSDN, Microsoft Docs, last edited on 02 Nov 2020
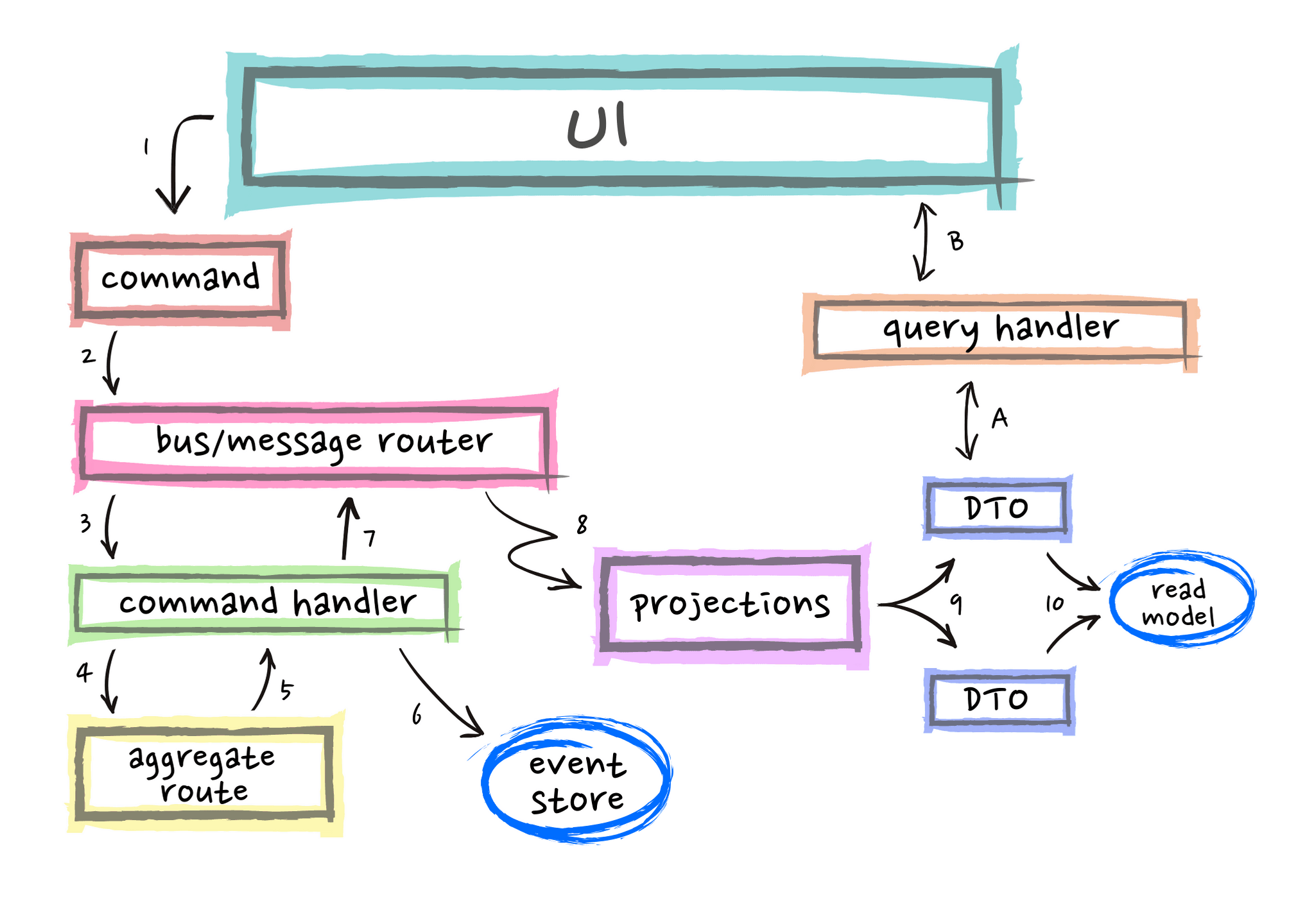 Fig. 24: Whittaker, Daniel. CQRS + Event Sourcing – Step by Step
Fig. 24: Whittaker, Daniel. CQRS + Event Sourcing – Step by Step
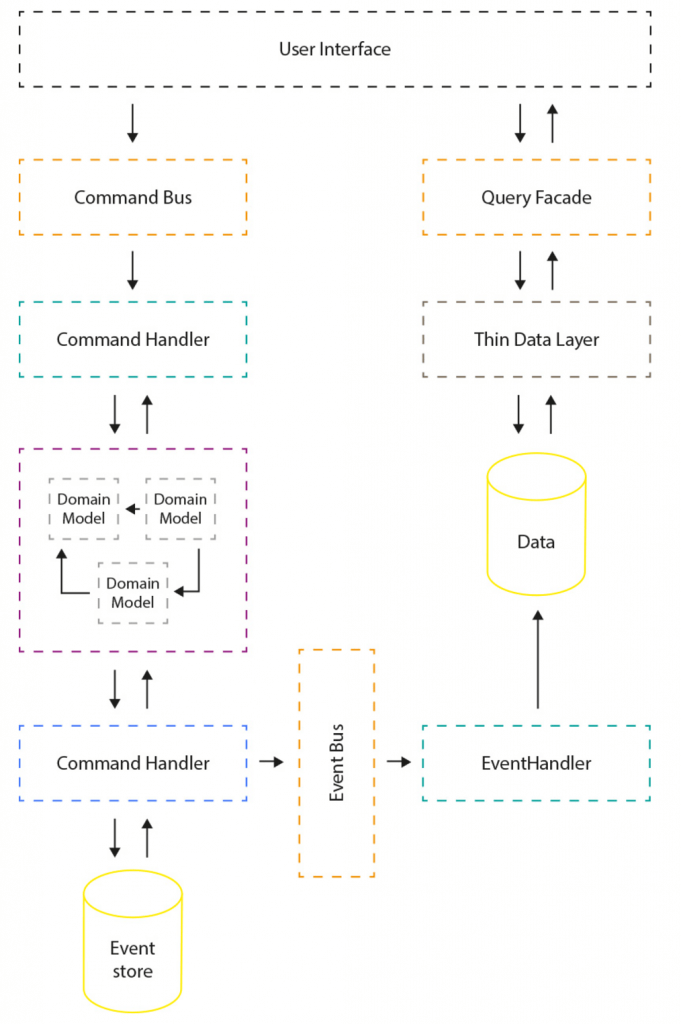
Fig. 25: Katwatka, Piotr. Event Sourcing with CQRS
Capability Map
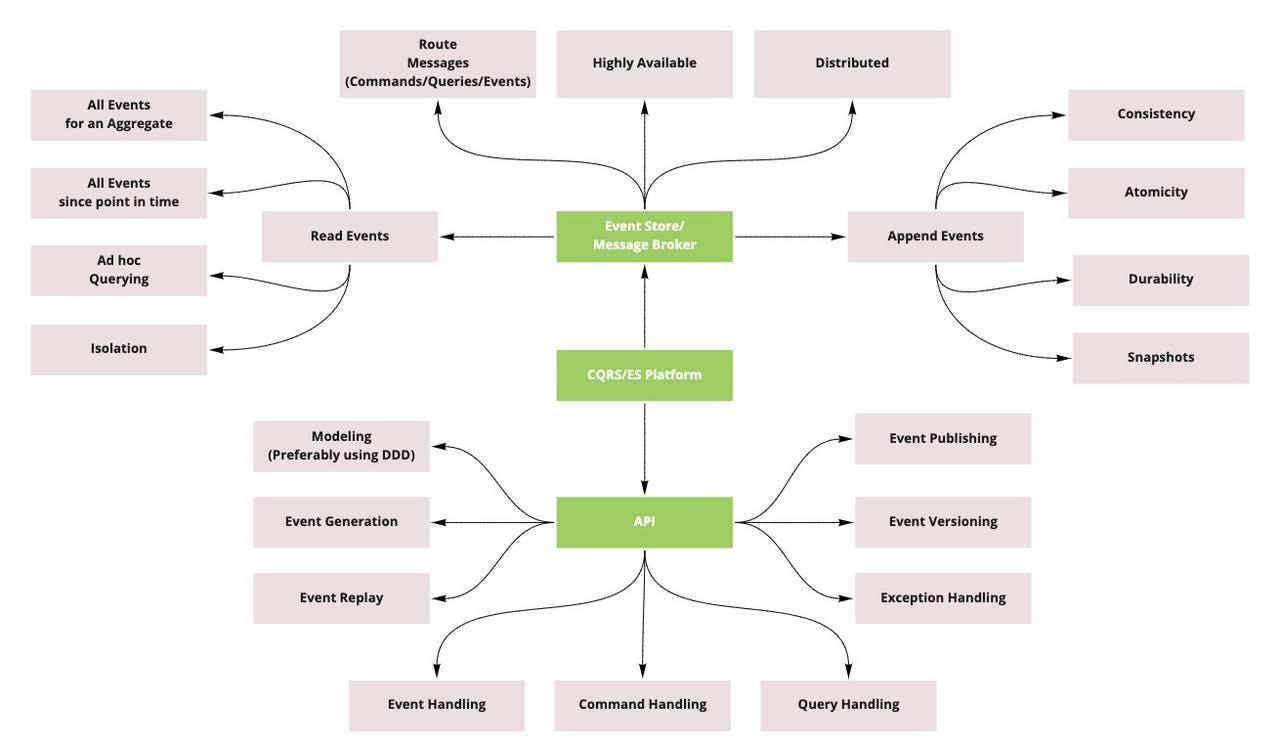 Fig. 26: Nair, Vijay. Distilling the CQRS/ES Capability
Fig. 26: Nair, Vijay. Distilling the CQRS/ES Capability
Commands vs Events
Events represent a past, something that already happened and can't be undone. Commands, on the other hand, represent a wish, an action in the future which can be rejected. An event has typically multiple consumers, but a command is addressed to only one.
Tulka, Tomas. "Events vs. Commands in DDD", blog.ttulka.com, last edited on 25 Mar 2020
Domain Event
In domain-driven design, domain events are described as something that happens in the domain and is important to domain experts. Such events typically occur regardless of whether or to what extent the domain is implemented in a software system. They are also independent of technologies. Accordingly, domain events have a high-value semantics, which is expressed in the language spoken by domain experts.
Stettler, Christina. "Domain Events vs. Event Sourcing", innoq.com, last edited on 15 Jan 2019
Event Sourcing is when you use Domain Events to store the state of an Aggregate within a Bounded Context. This basically means replacing your relational data model (or other data store) with an ever-growing log of Domain Events, which is called an event store. This is the core of Event Sourcing. So to use Event Sourcing you definitely need to understand Domain Events.
Holmqvist, Mattias. "What are Domain Events?", serialized.io, last edited on 20 Aug 2020
Integration Event
Integration events are used for bringing domain state in sync across multiple microservices or external systems. This functionality is done by publishing integration events outside the microservice. When an event is published to multiple receiver microservices (to as many microservices as are subscribed to the integration event), the appropriate event handler in each receiver microservice handles the event.
Should you publish Domain Events or Integration Events? Common advice is to not publish domain events outside of your service boundary. They should only exist within your service boundary. Instead, you should publish integration events for other service boundaries. While this general advice makes sense, it’s not so cut-and-dry. There are many reasons why you would want to publish domain events for other services to consume.
Domain Events or Integration Events? As always, it depends. If your domain events are stable business concepts and they are understood outside of your boundary as a part of a long-running business process, then yes, publishing domain events outside of your boundary are acceptable. If events are used for data propagation or are more CRUD in nature, then publish Integration Events.
Event Notification
Most times events used for notifications are generally pretty slim. They don’t contain much data. If a consumer is handling an event but needs more information, to, for example, react and perform some action, it might have to make an RPC call back to the producing service to get more information. And this is what leads people to Event carried State Transfer, so they do not have to make these RPC calls.
In this mode, the event producer sends a notification to the event system that a change has happened to the entity. The change itself was NOT specified in the event. Consumers are expected to query the read endpoint to understand the latest state of the data.
Event-Carried State Transfer
The most common way I see events being used and explained is for state propagation. Meaning, you’re publishing events about state changes within a service, so other services (consumers) can keep a local cache copy of the data.
This is often referred to as Event Carried State Transfer.
The reason services will want a local cache copy of another service’s data, is so they do not need to make RPC calls to other services to get data. The issue with making the RPC call is if there are issues with availability or latency, the call might fail. In order to be available when other services are unavailable, they want the data they need locally.
In stark contrast to the event notification model, the event-carried state transfer model puts the data as part of the event itself. There are two key variants to implementing this. Fine-Grained and Snapshots.
Summary Event
Instead of emitting each event, the original business process can keep all the events private. At the end of the process, the process emits a single Summary Event. This event is redundant, in the sense that it contains only information that was already available in the preceding events. Consumers, instead of being aware of every event, are now only listening to this Summary Event, which tells them everything they need to know, with little to no irrelevant (to them) information. Consumers do not need to track state changes during the process, because they get everything at the end, and can then act on them.
Task Based UI + CQRS
Task Based UI + CQRS
In a standard user interface (UI), the user typically edits or manipulates data directly. This allows the user to enter or modify the data synchronously, enabling the UI to respond to the user's actions in real-time (blocking the operation until the return).
In a task-based UI, on the other hand, the user typically expresses their intentions rather than editing the data directly. Task-based UIs provide users with the information and tools to complete specific tasks. They generally are organized around the steps or stages of the task, and give the user instructions, prompts, and input fields to enter or modify a specific piece of data.
Task Based UI can use asynchronous communication mechanisms to enable users to express their intentions asynchronously, without the need for the UI to wait for a response or confirmation from the system. For example, the UI may use a message queue or event bus to send commands or messages to the system, and the system may use the same mechanism to send updates or notifications back to the UI. This enable the UI to continue with other operations, such as querying the system for updated data or displaying a progress indicator to the user without waiting for a response from the system.
However, even though a way command does not require a return value or confirmation, it can still be validated and accepted by the CQRS system. When a way command is received by the write side of the CQRS system, it can be validated to ensure that it is well-formed and conforms to the rules and constraints of the system. If the command is valid, it can be accepted and processed, and the data can be updated or modified according to the instructions in the command. If the command is not valid, it can be rejected or ignored, and the data can be left unchanged.
Task-based UIs and CQRS can be used together to provide users with a flexible and efficient way to interact with a system and complete specific tasks. This can make them more efficient and user-friendly than more general-purpose UIs.
EventStorming
EventStorming
EventStorming is a flexible workshop format for collaborative exploration of complex business domains.
It comes in different flavours, that can be used in different scenarios:
- to assess health of an existing line of business and to discover the most effective areas for improvements;
- to explore the viability of a new startup business model;
- to envision new services, that maximise positive outcomes to every party involved;
- to design clean and maintainable Event-Driven software, to support rapidly evolving businesses.
The adaptive nature of EventStorming allows sophisticated cross-discipline conversation between stakeholders with different backgrounds, delivering a new type of collaboration beyond silo and specialisation boundaries.
Brandolini, Alberto. "EventStorming", EventStorming.com, last edited on 2020
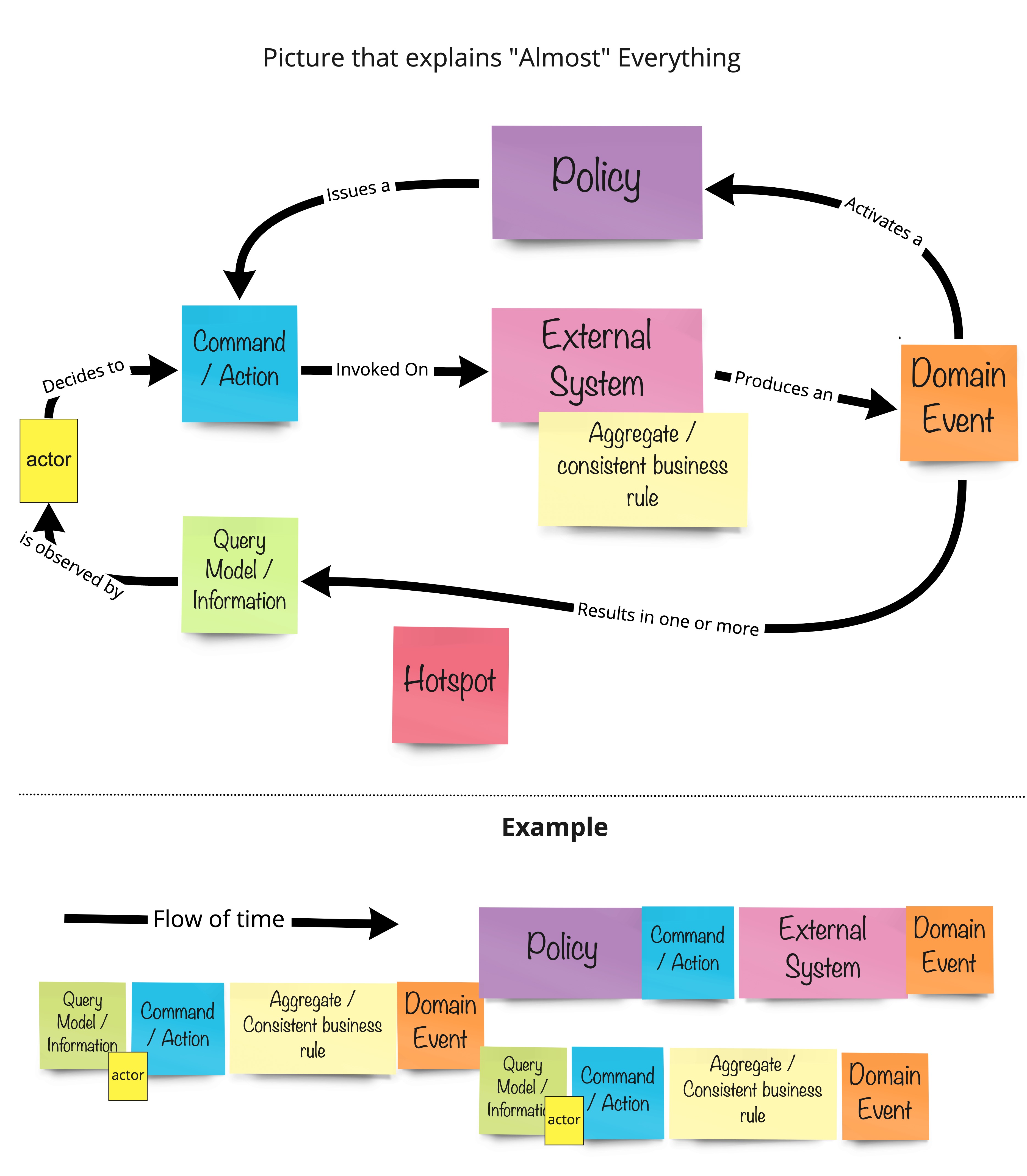
Fig. 27: Baas-Schwegler, Kenny & Richardson, Chris. Picture that explains "Almost" Everything
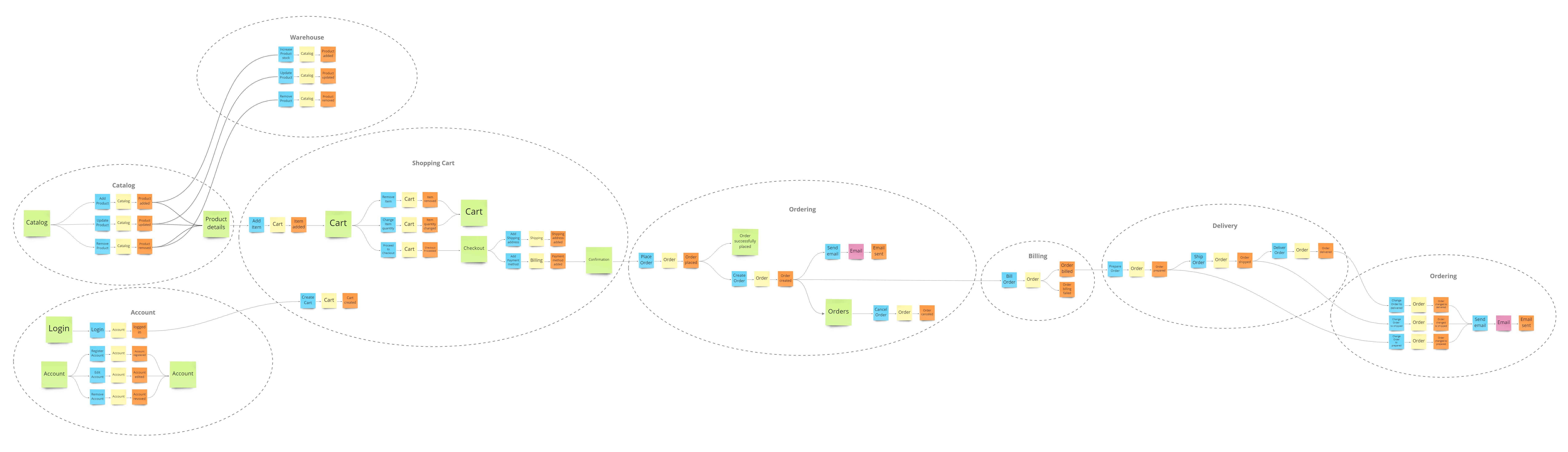
EventStorming (WIP)
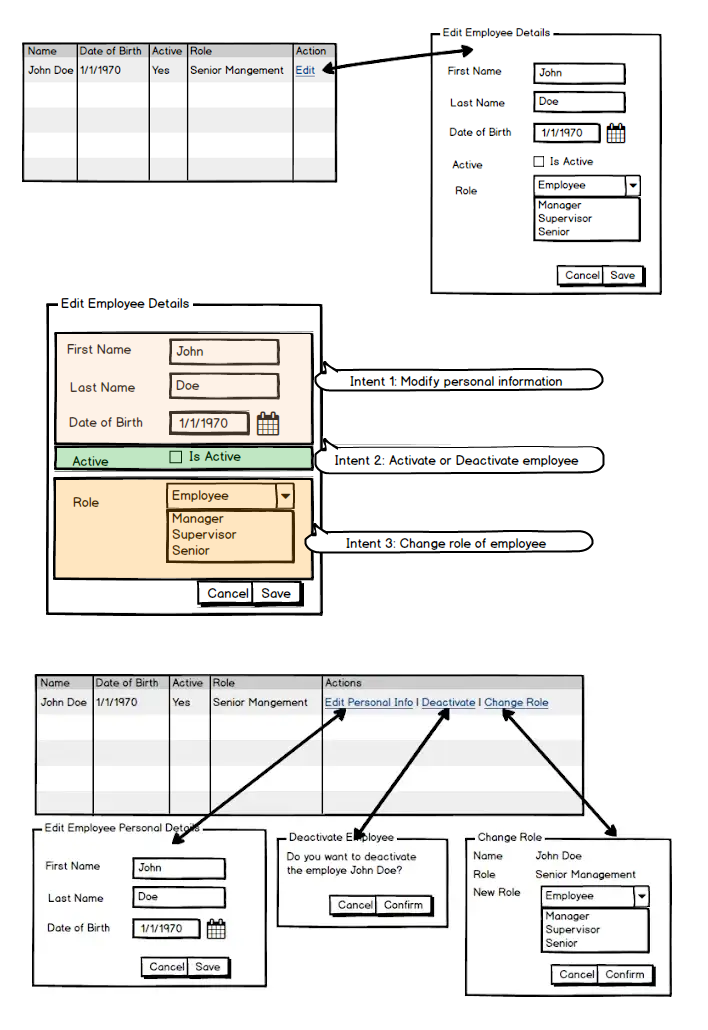
Authentication flow
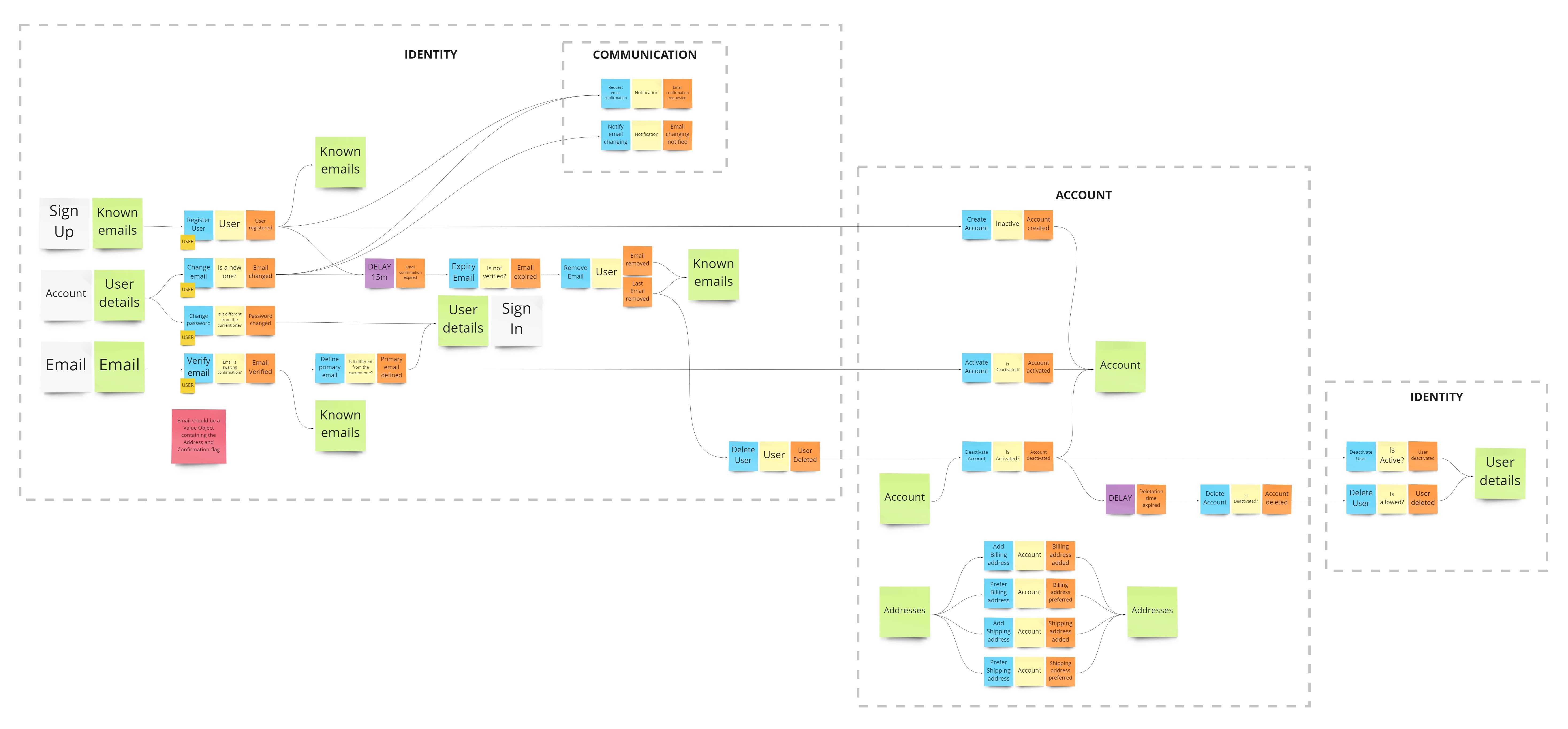
From EventStorming to Event Sourcing
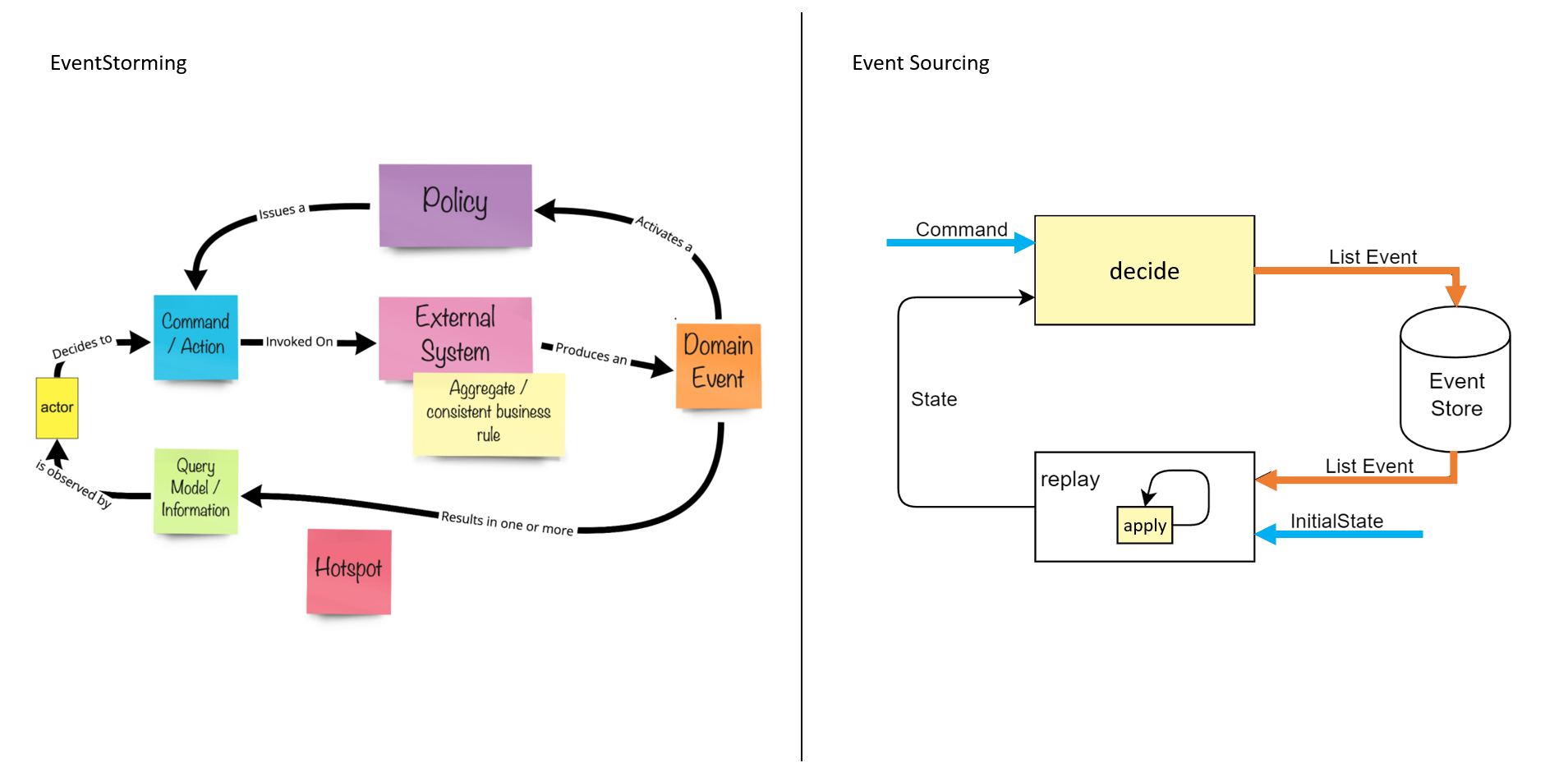
Clean Architecture
Clean Architecture
Clean architecture is a software design philosophy that separates the elements of a design into ring levels. An important goal of clean architecture is to provide developers with a way to organize code in such a way that it encapsulates the business logic but keeps it separate from the delivery mechanism.
The main rule of clean architecture is that code dependencies can only move from the outer levels inward. Code on the inner layers can have no knowledge of functions on the outer layers. The variables, functions and classes (any entities) that exist in the outer layers can not be mentioned in the more inward levels. It is recommended that data formats also stay separate between levels.
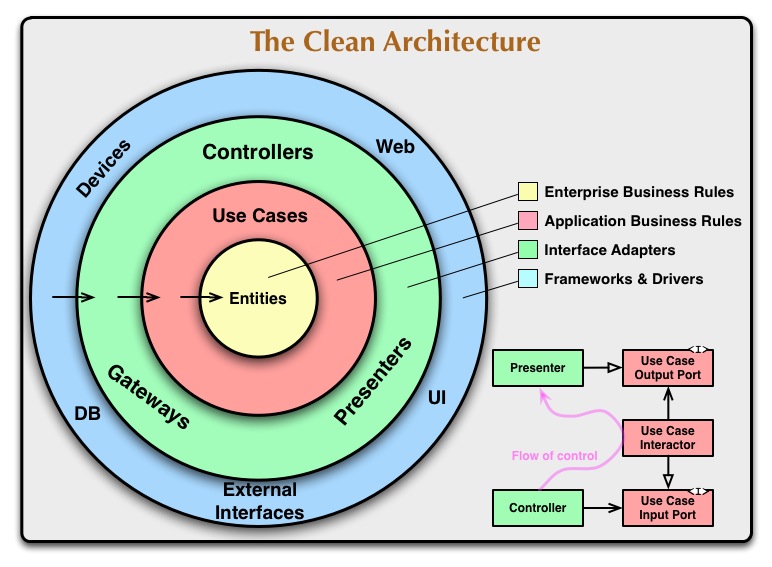
Fig. 28: C. Martin, Robert. The Clean Architecture
Diagram
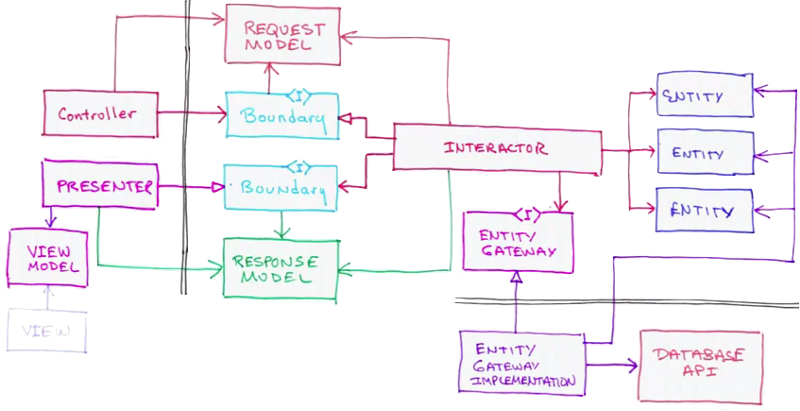
:rocket: Performance
Async Projections
Async Projections
In a Command and Query Responsibility Segregation (CQRS) system, denormalized asynchronous projections can significantly improve performance for several reasons:
-
Improved Read Performance: In a CQRS system, the read side is separate from the write side and is optimized for querying data. By denormalizing the data in the projections, the read side can access the data it needs more efficiently, reducing the number of joins required to retrieve data and ultimately speeding up query performance.
-
Reduced Latency: When data is denormalized, it's usually stored in a format that's more suitable for the specific use case. This can reduce the amount of data that needs to be retrieved from the database, which can help to minimize latency and improve the overall responsiveness of the system.
-
Increased Scalability: Denormalized projections can handle a larger volume of data more efficiently than normalized ones. This is because denormalized data is usually stored in a format that's optimized for a specific use case, which allows the system to process the data more quickly and with less resources.
-
Simpler Architecture: In a normalized data model, data is often spread out across multiple tables, which can make the system more complex to design, develop, and maintain. By denormalizing the data, it can be easier to manage and understand, which can simplify the overall architecture and make the system more maintainable.
-
Improved Concurrency: Asynchronous projections allow multiple operations to be performed at the same time and, denormalized projections reduce contention, helping to improve concurrent write operation performance.
In summary, denormalized asynchronous projections in a CQRS system can help to improve performance by reducing latency, increasing scalability, simplifying the architecture, and improving concurrency. This results in a more responsive and efficient system that can handle larger volumes of data and more complex queries.
Snapshotting
Snapshotting
Snapshotting is an optimisation that reduces time spent on reading event from an event store.
Gunia, Kacper. "Event Sourcing: Snapshotting", domaincentric.net, last edited on 5 Jun 2020
More details in snapshot section.
Minimize Exceptions
Minimize Exceptions
Exceptions should be rare. Throwing and catching exceptions is slow relative to other code flow patterns. Because of this, exceptions shouldn't be used to control normal program flow.
Recommendations:
- Do not use throwing or catching exceptions as a means of normal program flow, especially in hot code paths.
- Do include logic in the app to detect and handle conditions that would cause an exception.
- Do throw or catch exceptions for unusual or unexpected conditions.
- App diagnostic tools, such as Application Insights, can help to identify common exceptions in an app that may affect performance.
"ASP.NET Core Performance Best Practices" MSDN, Microsoft Docs, last edited on 18 Fev 2022
Pool HTTP connections with HttpClientFactory
Pool HTTP connections with HttpClientFactory
Closed
HttpClientinstances leave sockets open in theTIME_WAITstate for a short period of time. If a code path that creates and disposes ofHttpClientobjects is frequently used, the app may exhaust available sockets.Recommendations:
- Do not create and dispose of HttpClient instances directly.
- Do use HttpClientFactory to retrieve HttpClient instances.
"ASP.NET Core Performance Best Practices" MSDN, Microsoft Docs, last edited on 18 Fev 2022
DbContext Pooling
DbContext Pooling
The basic pattern for using EF Core in an ASP.NET Core application usually involves registering a custom DbContext type into the dependency injection system and later obtaining instances of that type through constructor parameters in controllers. This means a new instance of the DbContext is created for each request.
In version 2.0 we are introducing a new way to register custom DbContext types in dependency injection which transparently introduces a pool of reusable DbContext instances. This is conceptually similar to how connection pooling operates in ADO.NET providers and has the advantage of saving some of the cost of initialization of DbContext instance.
"New features in EF Core 2.0" MSDN, Microsoft Docs, last edited on 11 Oct 2020
:computer: Running
Projects may have different environments where the application runs: development, staging, production, etc. Usually, different environments should have different settings.
Development
Development
Development is usually a local environment. Docker makes it easy to set up that closely mirrors the production environment without having to install and configure all of the dependencies on your local machine. Especially useful for working on complex applications that rely on many different libraries and tools.
Docker
The respective ./docker-compose.Development.Infrastructure.yaml will provide all the necessary resources, with public exposure to the connection ports:
docker-compose -f ./docker-compose.Development.Infrastructure.yaml up -d
If prefer, is possible to use individual Docker commands:
MSSQL
docker run -d \
-e 'ACCEPT_EULA=Y' \
-e 'SA_PASSWORD=!MyStrongPassword' \
-p 1433:1433 \
--name mssql \
mcr.microsoft.com/mssql/server
MongoDB
docker run -d \
-e 'MONGO_INITDB_ROOT_USERNAME=mongoadmin' \
-e 'MONGO_INITDB_ROOT_PASSWORD=secret' \
-p 27017:27017 \
--name mongodb \
mongo
RabbitMQ
docker run -d \
-p 15672:15672 \
-p 5672:5672 \
--hostname my-rabbit \
--name rabbitmq \
rabbitmq:3-management
Staging
Staging
The staging environment is for testing and homologation; It resembles the production environment. In other words, it's a complete but independent copy of the production environment, including seeding data if needed.
Based on a containerized system, the staging environment is provided via Docker Compose. On each appsettings.Staging.json the integrations are configured by name, taking advantage from the Docker
network interface with DNS services.
Docker-compose
The resources were split into two files:
docker-compose.Staging.Infrastructure.yaml, connection ports are privately exposed only;docker-compose.Staging.Services.yaml, services connected by DNS names.
docker-compose \
-f ./docker-compose.Staging.Infrastructure.yaml \
-f ./docker-compose.Staging.Services.yaml \
up -d
Deployment
Replicas count and resources allocation can be configured straight on respective composes files:
deploy:
replicas: 2
resources:
limits:
cpus: '0.20'
memory: 200M
Production
Production
// TODO
Migrations
EF Core Migrations
If it's needed to change the Event Store structure, a new migration should be built:
dotnet ef migrations add "First Migration" -s .\WorkerService\ -p .\Infrastructure.EventStore\
The database update is automatically executed at the command-stack Worker Services Program.cs, for Development and Staging environments:
var environment = host.Services.GetRequiredService<IHostEnvironment>();
if (environment.IsDevelopment() || environment.IsStaging())
{
await using var scope = host.Services.CreateAsyncScope();
await using var dbContext = scope.ServiceProvider.GetRequiredService<EventStoreDbContext>();
await dbContext.Database.MigrateAsync();
await dbContext.Database.EnsureCreatedAsync();
}
:test_tube: Tests
Unit Tests
Unit Tests
To unit-test an event-sourced aggregate, it's to verify that the Aggregate produces the expected event as output given a specific set of input Events and a Command. This involves creating an Aggregate instance, applying the input events to it, handling the command, and verifying the expected event output.
[Fact]
public void CreateCartShouldRaiseCartCreated()
=> Given<ShoppingCart>()
.When<Command.CreateCart>(new(_cartId, _customerId))
.Then<DomainEvent.CartCreated>(
@event => @event.CartId.Should().Be(_cartId),
@event => @event.CustomerId.Should().Be(_customerId),
@event => @event.Status.Should().Be(CartStatus.Active));
Integration Tests
Integration Tests
// TODO
Load Tests
Load Testing (K6)
docker run --network=internal --name k6 --rm -i grafana/k6 run - <test.js
:book: References
Books
- Evans, Eric (2003), Domain-Driven Design: Tackling Complexity in the Heart of Software.
- Hohpe, Gregor (2003), Enterprise Integration Patterns: Designing, Building, and Deploying Messaging Solutions
- Young, Greg (2012), Event Centric: Finding Simplicity in Complex Systems.
- Vernon, Vaughn (2016), Domain-Driven Design Distilled.
- Richardson, Chris (2018), Microservices Patterns: With examples in Java.
Articles
- Effective Aggregate Design Part I: Modeling a Single Aggregate
- Effective Aggregate Design Part II: Making Aggregates Work Together
- Effective Aggregate Design Part III: Gaining Insight Through Discovery
- CQRS Documents - Greg Young
- Versioning in an Event Sourced - Greg Young
- Clarified CQRS - Udi Dahan
Blogs
- Event-driven IO - Oskar Dudycz
- Code Opinion - Derek Comartin
- Domain Centric - Kacper Gunia
- CQRS Event Sourcing - Daniel Whittaker
- Event Store - Alexey Zimarev
- Mathias Verraes Student of Systems
Posts
- Modeling Uncertainty with Reactive DDD - Vaughn Vernon
- Reactive DDD—When Concurrent Waxes Fluent - Vaughn Vernon
- Pattern: Event sourcing - Chris Richardson
- Clarified CQRS - Udi Dahan
- Udi & Greg Reach CQRS Agreement
- Event Sourcing and CQRS - Alexey Zimarev
- What is Event Sourcing? - Alexey Zimarev
- Transcript of Greg Young's Talk at Code on the Beach 2014: CQRS and Event Sourcing
- Introduction to CQRS - Kanasz Robert
- Distilling the CQRS/ES Capability - Vijay Nair
- Dispelling the Eventual Consistency FUD when using Event Sourcing - Vijay Nair
- Why would I need a specialized Event Store? - Greg Woods
- A Fast and Lightweight Solution for CQRS and Event Sourcing - Daniel Miller
- Event Sourcing: The Good, The Bad and The Ugly - Dennis Doomen
- What they don’t tell you about event sourcing - Hugo Rocha
- Event Sourcing pattern - MSDN
- CQRS + Event Sourcing, Step by Step - Daniel
- Architectural considerations for event-driven microservices-based systems - Tanmay Ambre
- How messaging simplifies and strengthens your microservice application - Callum Jackson
- Event Sourcing: Aggregates Vs Projections - Kacper Gunia
- Event Sourcing: Projections - Kacper Gunia
- Advantages of the event-driven architecture pattern - Grace Jansen & Johanna Saladas
- CQRS - Martin Fowler
Projects
:toolbox: Tech Stack
Worker Services
- .NET 8 - A free, multi/cross-platform and open-source framework;
- EF Core 8 - An open source object–relational mapping framework for ADO.NET;
- MSSQL - A relational database management system (Event Store Database);
- MongoDB - A source-available cross-platform document-oriented database (Projections Database);
- MassTransit - Message Bus;
- FluentValidation - A popular .NET library for building strongly-typed validation rules;
- Serilog - A diagnostic logging to files, console and elsewhere.
Web API
- ASP.NET Core 8 - A free, cross-platform and open-source web-development framework;
- MassTransit - Message Bus;
- FluentValidation - A popular .NET library for building strongly-typed validation rules;
- Serilog - A diagnostic logging to files, console and elsewhere.
Web APP
- Blazor WASM - Is a single-page app (SPA) framework for building interactive client-side web apps with .NET;
- BlazorStrap - Bootstrap 5 Components for Blazor Framework;
Contributing
All contributions are welcome. Please take a look at contributing guide.
Versioning
We use SemVer for versioning. For the versions available, see the tags on this repository.
Authors
See the list of contributors who participated in this project.
License
This project is licensed under the MIT License - see the LICENSE file for details